We, at Qubole, are excited to announce the General Availability of the Qubole data platform on Google Cloud – a self-service, collaborative, enterprise platform for data engineering, predictive analytics, and machine learning. The platform enables data scientists and data engineers on Google Cloud Platform (GCP) to collaborate on building scalable data pipelines using native interfaces, built-in tools, and optimized data processing engines. From its inception, we have closely partnered with Google product and engineering teams to build and launch the Qubole data platform on GCP.
Key benefits of the platform include:
- Unified and rich experience with built-in end-user tools such as native notebooks, an integrated workbench for commands, and in-built connectors to multiple data sources.
- Highly optimized versions of data processing engines such as Apache Spark, Hive, and Airflow for better performance and efficiency.
- Enterprise support for data processing engines such as Apache Spark, Hive, and Airflow by specialized engineering teams focused on each engine.
- Advanced automation and cluster lifecycle management that enables cloud-scale deployments within fixed budgets while maintaining low administrative overhead.
- Enterprise-grade security with fine-grained access controls to data and platform resources such as clusters, notebooks, commands, and more.
- Deep integration with Google services such as Google Compute Engine, Google Cloud Storage, BigQuery storage, preemptible Virtual Machines (VMs), and Cloud Identity and Access Management (IAM).
- Fast access from GCP Marketplace with flexible purchase plans, automated service setup, and simplified user onboarding.
Architecture Patterns and Use Cases
Next, we will look at common architecture patterns and use cases with Qubole.
Data Ingestion and Transformation
Data engineers can build scalable pipelines for batch and streaming ingestion of data into Google Cloud Storage or BigQuery storage. They can use Qubole’s Spark or Hive to perform data transformations, including complex joins or conversions to Apache Avro, Parquet, and ORC formats for downstream use cases like Machine Learning (ML) or data exploration. They can use Qubole’s built-in workbench to execute Spark and Hive queries or use Qubole’s Airflow service to build and orchestrate scalable data pipelines in GCP.
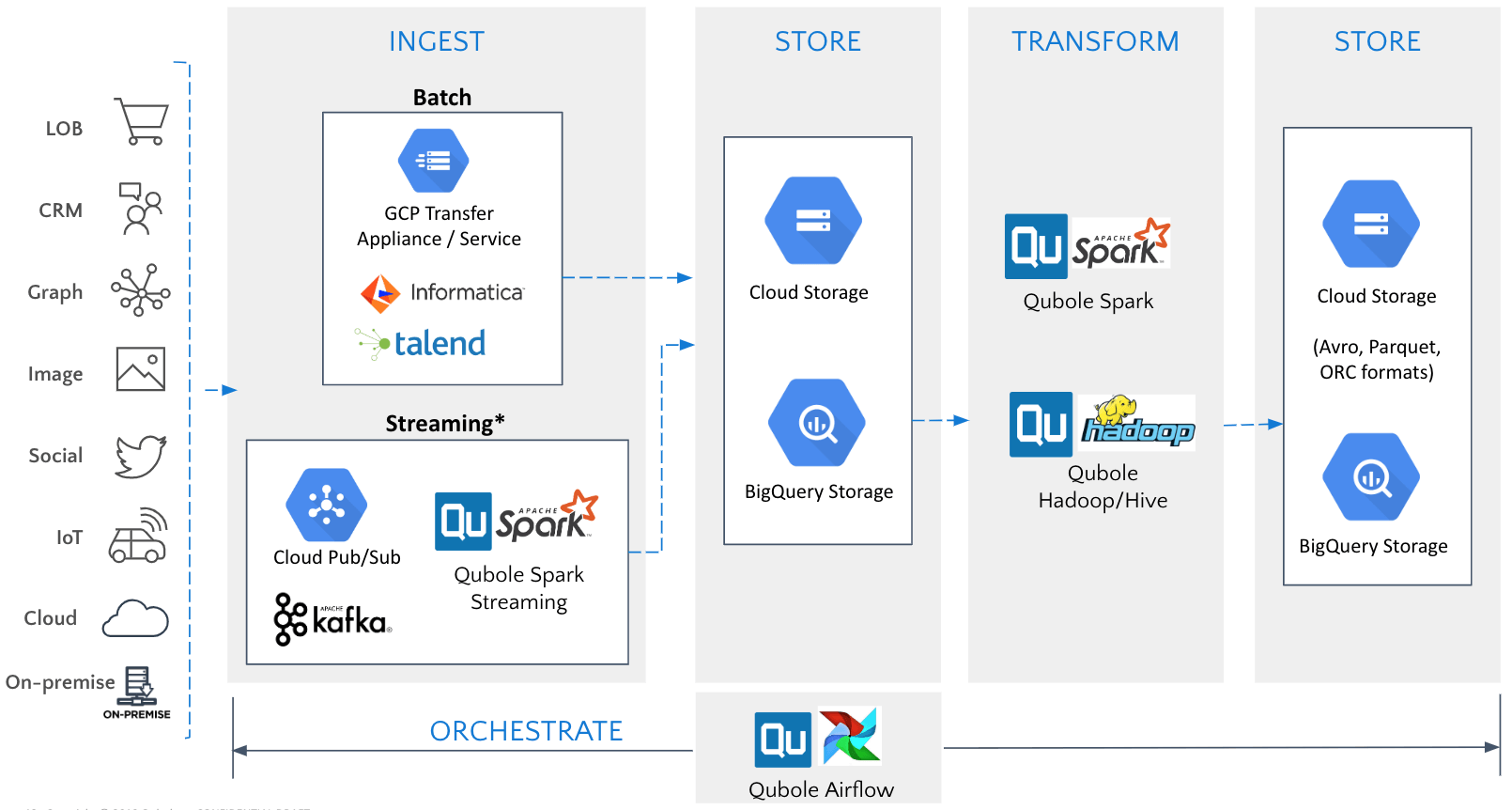
* Streaming support for Qubole on GCP coming soon
Machine Learning and Predictive Analytics
Data Scientists can use Spark on Qubole and its native notebook interface to build and train ML models using data from Google Cloud Storage or BigQuery. They can develop models in multiple languages such as Python, Scala, SQL, and R. They can add additional Conda packages and manage dependencies between packages using Qubole package management. Qubole’s unified interface built for collaborative development enables users to share notebooks, schedule jobs, and publish results to dashboards for easy visualization and consumption by business users.
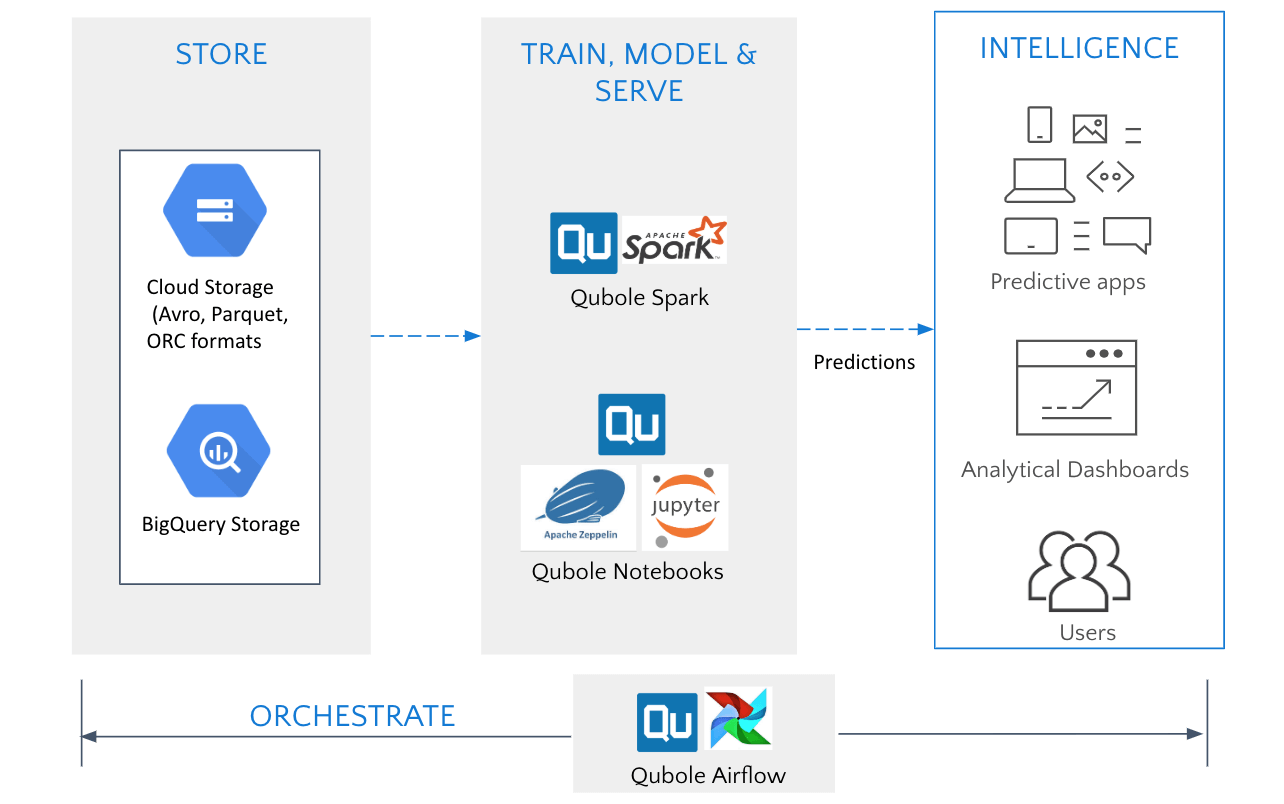
Data Discovery and Business Intelligence (BI)
Data analysts use Presto on Qubole for data discovery and BI, including reporting and dashboards. Presto is based on a Massively Parallel Processing (MPP) design that can process interactive queries at high speed and scale. What makes Presto unique is its ability to run federated queries across multiple sources such as Google Cloud Storage, BigQuery storage, databases such as MySQL, Postgres, and MongoDB, and real-time data streaming applications such as Kafka. Qubole’s pricing model, based on computing hours used instead of data scanned, combined with its capability to autoscale and automatically terminate clusters, provides a cost-effective option for data analysts to perform exploratory analytics and data discovery at a petabyte-scale.
Data analysts can also use Qubole’s Presto to run reports directly off a data lake, or load periodic aggregates of the raw data into BigQuery for low latency reporting in Looker or Tableau leveraging certified connectors. In addition, Qubole offers native notebooks for Presto to enable data analysts to easily build interactive queries.
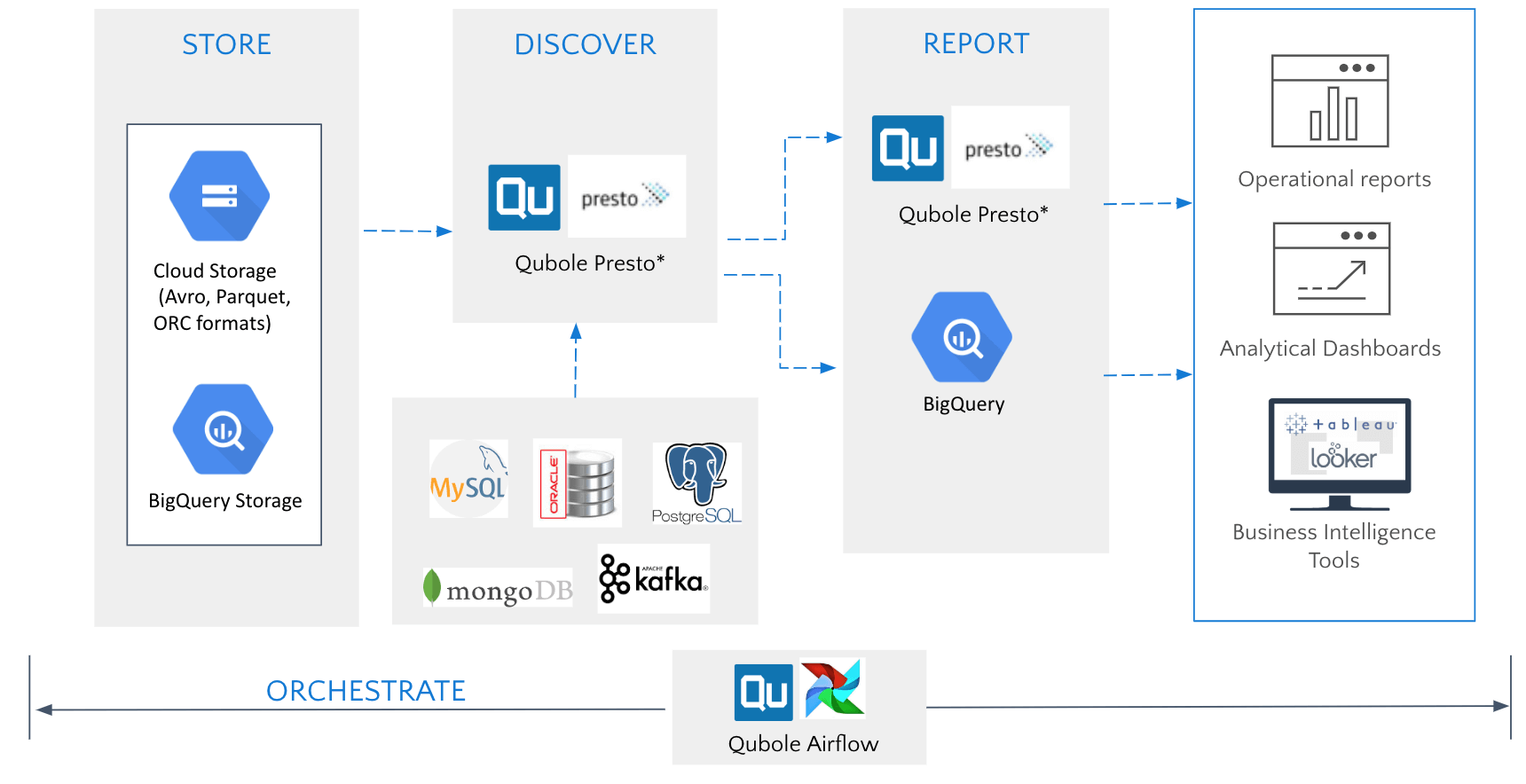
Qubole Data Platform Highlights
Since we launched the public preview of the Qubole Data Platform on GCP in April, we have added several exciting capabilities to the platform such as integration with BigQuery storage, Qubole Presto support, and preemptible VM enhancements to offer enhanced scalability, cost efficiency, and deeper integration with Google Cloud services.
Integration with BigQuery
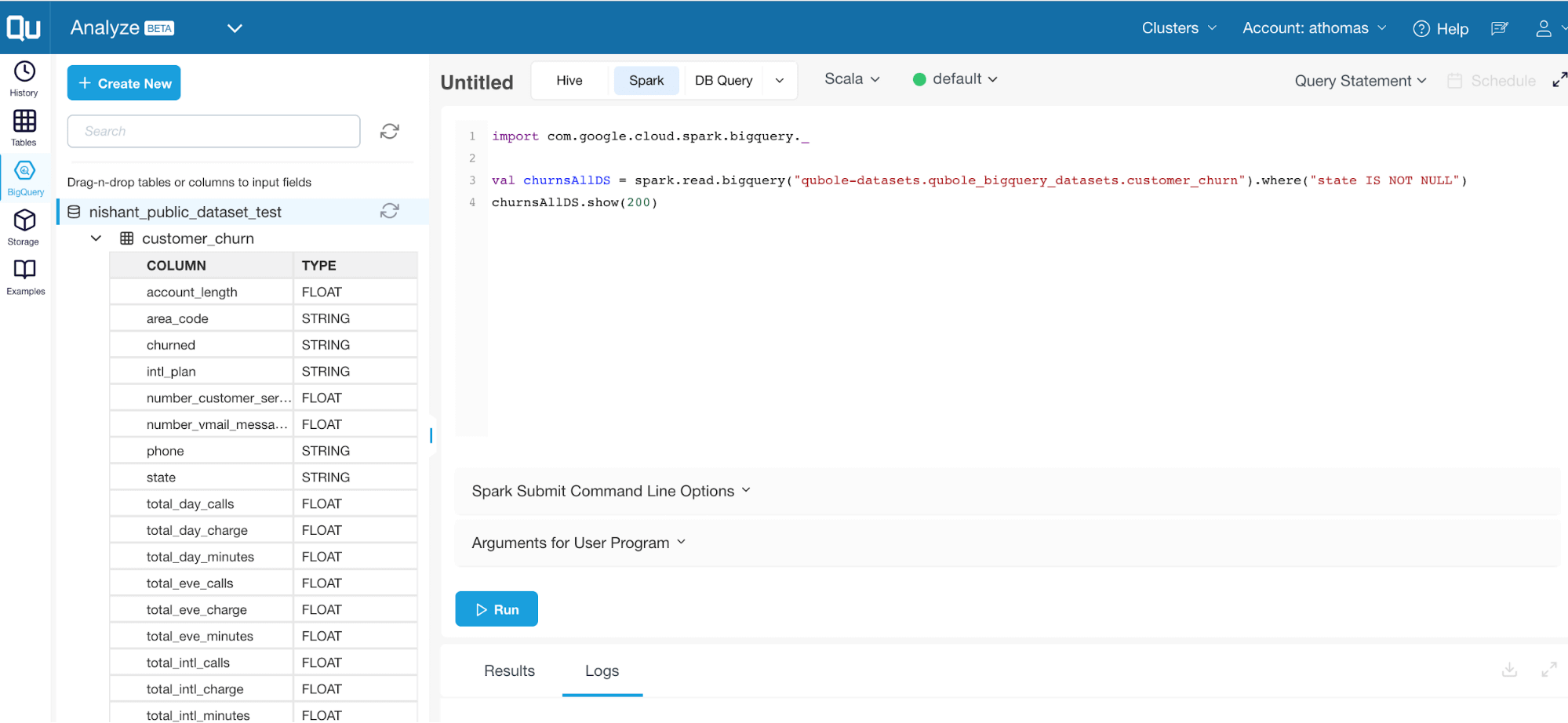
Spark on Qubole is integrated with BigQuery to enable direct reads of data from BigQuery storage into Spark Dataframes. This allows data engineers to easily explore BigQuery datasets or join data in Google Cloud Storage and BigQuery to perform complex data transformations and queries. Data scientists can now easily look up BigQuery datasets and build machine learning models using Qubole’s Spark and notebooks, resulting in significant time savings and efficiency gains for both data engineers and scientists.
The data is read in Apache Avro format using parallel streams with dynamic data sharding across streams to support low latency reads. This connector eliminates the need to export data from BigQuery to Google Cloud Storage, thereby significantly improving data processing times. Learn more about the BigQuery Storage API and its advantages such as direct reads, dynamic sharding, predicate filtering, column filtering, and more.
In addition to Qubole’s Spark connector for BigQuery storage, the platform also shows BigQuery datasets directly in Qubole’s command workbench and notebooks interfaces (see screenshots below). This allows data scientists and engineers to easily discover BigQuery tables and datasets from within Qubole.
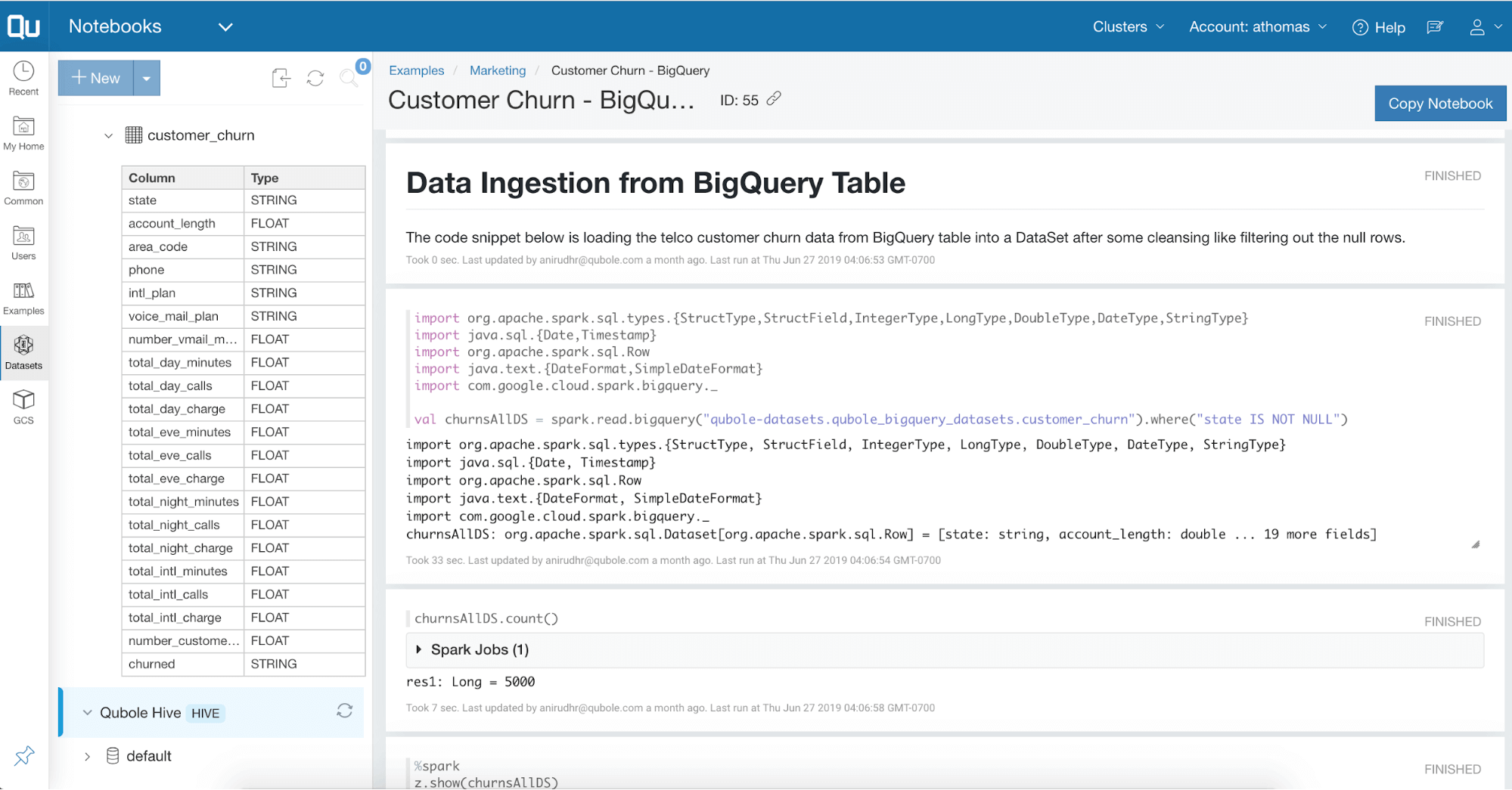
Autoscaling with Preemptible VMs
Qubole’s data platform allows data teams to run clusters at scale while still maintaining low cloud costs and high reliability through strong integration with GCP preemptible VMs. Administrators can now select a mix of regular and preemptible instances and specify the percentage of preemptible VMs desired on a per cluster basis. The platform fully handles acquiring and managing preemptible instances, and resiliently handles the loss of these instances without any intervention needed from platform administrators. Key capabilities include:
- Fallback to On-demand VMs: Qubole can fall back to using regular VM instances in a cluster when preemptible instances are not available during auto-scaling. This ensures that jobs complete within a reasonable time, while still making the best effort to contain costs by using preemptible instances when available.
- Cluster Rebalancing: Qubole has the ability to automatically rebalance clusters and retire excess regular nodes when the ratio of regular to preemptible VM instances exceeds the desired ratio requested by the user. This typically happens when we are either unable to use enough preemptible instances during cluster upscaling, or when we removed more preemptible than regular (on-demand) instances during downscaling. Rebalancing works by automatically swapping out regular instances for preemptible instances at the right time when preemptible instance availability is higher.
- Resiliency and Preemption Handling: Qubole uses several measures to provide a reliable integration with preemptible VM instances.
- HDFS Placement Policy: Qubole uses an HDFS block placement policy, which ensures that at least one replica of a file local to a preemptible instance resides on a stable, regular instance. This ensures that if the cluster loses a preemptible instance, a replica of the data continues to exist on regular instances. This allows all preemptible instances to participate as data nodes in the cluster without compromising the availability and integrity of HDFS. As a result, the storage capacity of the cluster increases, and user jobs are no longer constrained to using only the core cluster nodes.
- Intelligent Task Placement: Important jobs like Application Master and shell commands that often launch other long-running jobs, are never scheduled on preemptible VM instances.
- Reliable Preemption Handling: When instances get preempted by Google, Qubole immediately stops scheduling new tasks on these nodes. It also stops further HDFS writes to these nodes, backs up container logs, and tries to replicate any state left on such nodes to other surviving nodes. Application masters are automatically notified to restart interrupted tasks on other nodes in the cluster, and cluster autoscaling logic kicks in to replace the lost node with a new preemptible VM, should it be available and within policy.
Presto on Qubole
Qubole data platform now supports Presto in addition to Spark, Hive, and Airflow. This enables customers to perform data discovery, profiling, and BI reporting directly off their data lake in GCP. Qubole’s Presto includes a connector to Google Cloud Storage, the ability to autoscale using preemptible VMs, and supports Qubole’s JDBC driver on GCP. Customers can use Presto to perform the discovery of datasets in Google Cloud Storage to figure out patterns and trends, profile datasets to identify quality or integrity issues, query the data to answer specific questions, and finally publish results to BI tools for consumption by business users. Certified connectors to BI tools like Looker and Tableau will be made available shortly.
Native Jupyter Notebooks
Qubole data platform offers a JupyterLab notebook interface for data scientists. JupyterLab is a web-based interactive development environment for Jupyter notebooks, code, and data. In addition to the rich and usable JupyterLab interface, Qubole notebooks provide additional features like a per-user folder with automatic code persistence, library dependence management for clusters, easy access to Spark resources, and automatic Spark application lifecycle management, and enhanced UI widgets such as application progress meter. The interface is available as a private preview.
Custom Commit Plan on GCP Marketplace
You can easily procure Qubole Data Service from GCP Marketplace with integrated billing; this means you receive a single bill from Google for all GCP services including Qubole. With this release, we have added the option of a Custom Commit Plan on Marketplace, in addition to the existing, flexible pay-as-you-go Essentials Plan. This enables large enterprises to purchase Qubole Data Service using annual and multi-year subscriptions, with the ability to customize the terms of purchase with personalized discounts and private quotes.
Conclusion
We are excited to launch with Google the General Availability of Qubole on GCP. It enables data teams to run big data analytics at scale using a self-service model with built-in tools, enterprise support for open-source engines, and advanced automation that lowers administrative burden and cloud costs.
Qubole is available in the Google Cloud Platform Marketplace today. For more information about how Google and Qubole simplify multi-cloud data processing, check out Google’s blog post. To learn more, visit our Qubole on the GCP webpage or sign up for Qubole Data Service on GCP Marketplace.
.blog.single #old-banner {background-position: 50% 75% !important; }



