Data Management
- Home >
- Platform >
- Open Data Lake Platform >
- Data Management
Build and manage metadata, discover and explore data dependencies and statistics, to improve workload performance.
Faster Data Discovery
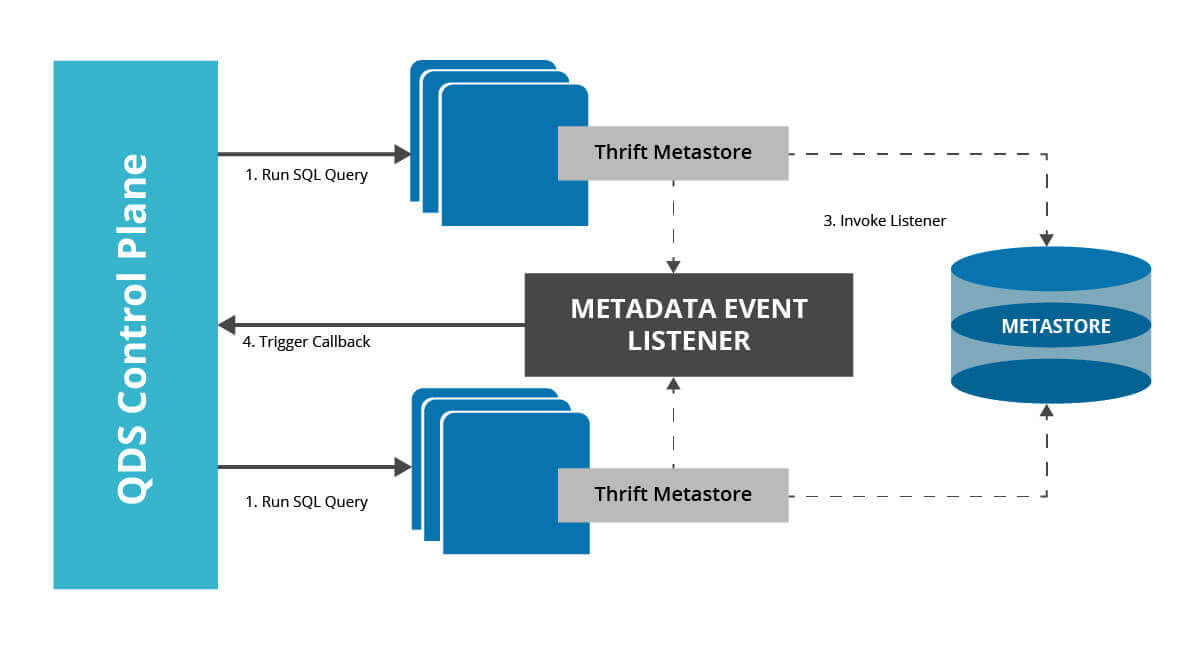
Use single metastore for different open source engines to define and classify data and build a unified catalog of governable data assets.
Leverage single catalog for ad-hoc analytics, data exploration, streaming analytics and machine learning use cases. Do audit and compliance monitoring with data usage and lineage.
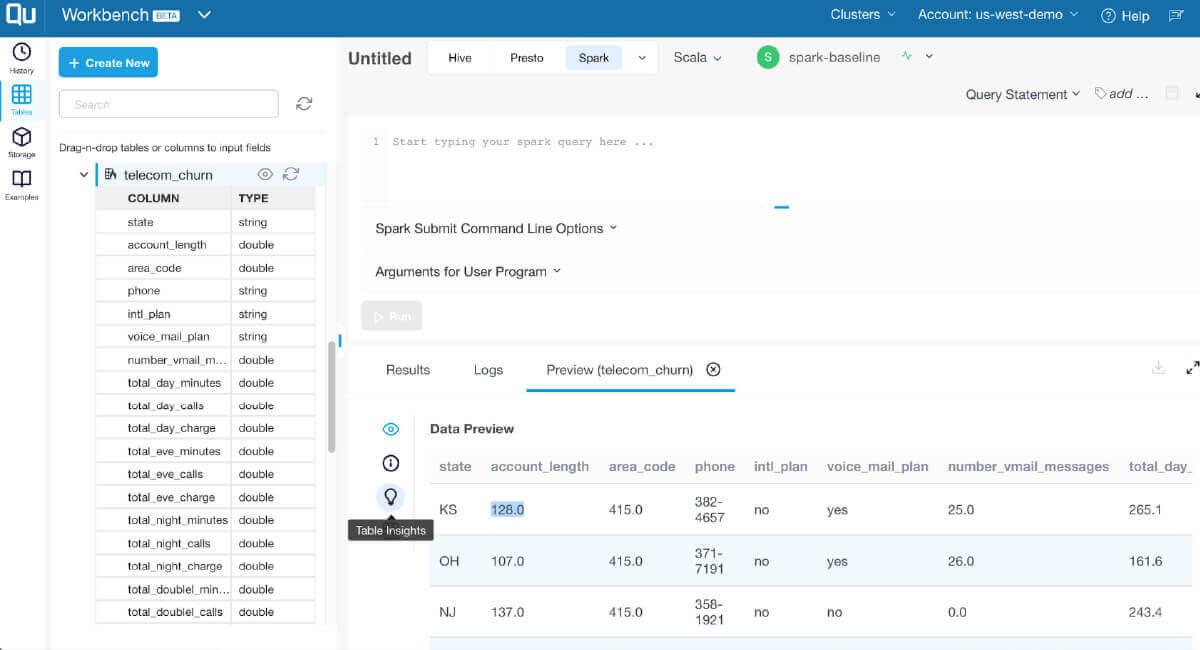
Quicker Response Time
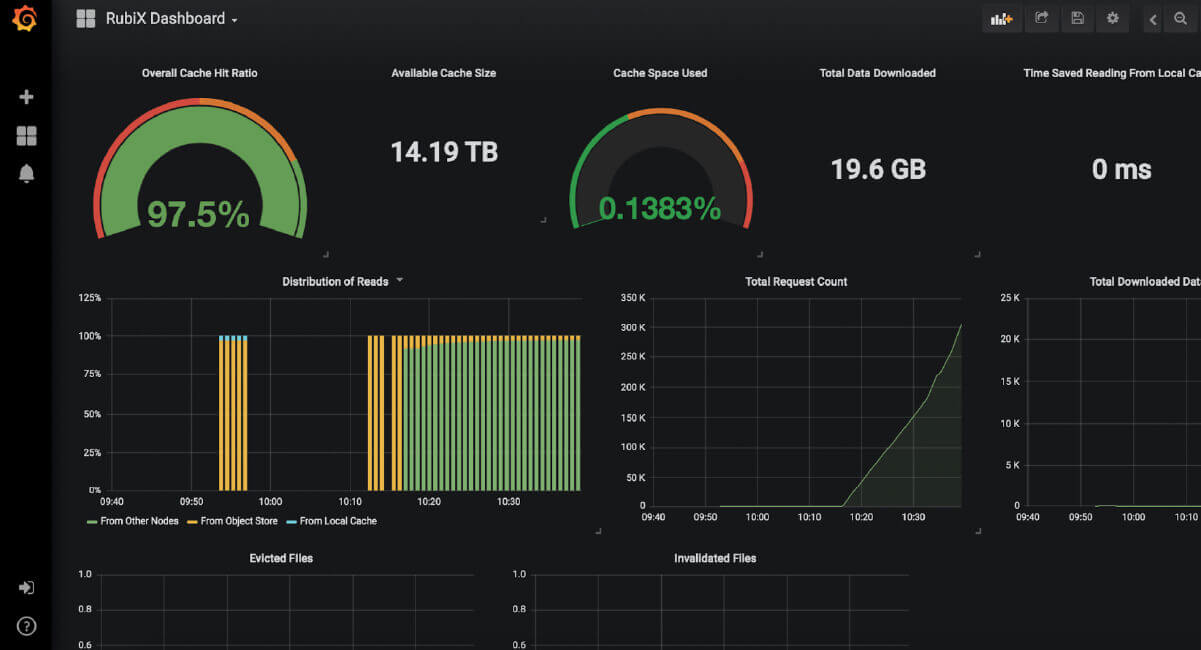
Leverage Rubix, a lightweight, underlying engine agnostic, data caching framework for quick response to most sought after queries.
Work with leading public cloud storage systems like AWS S3, Google Cloud Storage and Azure Blob Storage and open source engines Apache Hive, Apache Spark and Presto
Automated Statistics Collection
Get automated table stats collection. Combine with Presto, Apache Spark, and Apache Hive generated efficient query plans to experience maximum performance and efficiency for discovering and profiling datasets.

Open Data Format
Choose the data format best suited for your workload. No vendor lock-in with a particular format and leverage open source compliant formats.


