This is Part 2 of a 2 blog series on this topic. You can read Part 1 here.
Rollout Strategy:

We have different tiers in our tech stack. Rails mostly run in the web app and worker tier which are responsible for clients’ HTTP requests and background processing respectively.
Since we had limited QA bandwidth, we decided to start the rollout with the Worker tier which is a little less prone to failure than the web app tier where we had done many patches in big gems like devise.
We followed these steps for the rollout :
- Performed Mini and Full regressions with different combinations of worker tier configs: Rails N (release R, R+1); Rails N+1 (release R+1) where N represents the Rails version and R represents the Release version.
- Created cron expressions on the logs server to identify if there was an increase in the frequency of certain kinds of errors.
- Created script to manually clear bad cache from prod env if in case it was created.
- Set up a dashboard on Signal Fx to check different metrics.
Still, after all the QA testing there will be issues you will only hit on production envs. Some of the issues we encountered proactively on prod env were:
- Command completion emails were not being sent:
Users can subscribe to emails for command completion. After the rollout, we checked the application logs and found out that there were some exceptions while sending the email notifications for command completion. The issue was that the definition for one of the distance_of_time_in_words ( Rails method) was changed. - Command execution delay in bigger environments:
Caused by using the OpenStruct issue that has been discussed above. - Cluster clean up background job got stuck:
The cluster cleanup background job was getting stuck because of a bad query that was being formed. The bad query was formed because the first method behaved differently in the newer Rails version than the older Rails version. In the newer Rails version, the first method adds an order by a clause which caused our queries to not use the underlying indexes on the table and these queries ran for hours.
More info here.
How was it decided that a particular node should come up in Rails N (older version) or Rails N+1 (newer version):
We use chef for our deployment on the AWS cloud. We make use of the launch configuration for running our chef-client on the ec-2 instance that comes up to install various services. We made use of this launch configuration to set the environment variable RAILS_NEXT=1 if it was specified in the chef databag.
The chef databag entry looked something like the following:

Here 56.0 and 56.1 represent the two releases respectively and the web app, worker represents the tiers for which the rails_next flag should be enabled.
The rollout of the worker tier took about 3 weeks in all 5 environments. After upgrading the worker tier to the newer Rails version, we went ahead with the task of upgrading the Webapp tier.
We ran multiple iterations of Mini and Full regression tests to check the stability of the Rails app with the newer Rails version with all the combinations we could’ve encountered in production.
Issues that we hit during the upgrade of the web app tier in production:
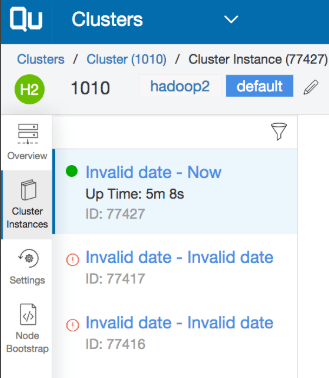
- Invalid date/time was displayed on UI (Safari and Firefox browser) in cluster and Scheduler page because of time format change between the two Rails versions. The date format in APIs has changed from iso8601 (eg. “2019-05-28T09:49:07Z”) to a string with UTC time format (Eg. “2019-05-28 09:46:21 UTC”) when the object is serialized with JSON format.

- Recent dashboards were not getting populated on the Qubole homepage because of missing attributes error. The missing attribute error was caused by assigning a custom attribute to the ActiveRecord object. This worked fine in the older Rails version but was displaying MissingAttributeError in the newer Rails version. We solved it by adding the custom attribute in attr_accessor.
- Some REST API calls were taking a long time when using rest-client. This was because of the longer default timeout(60seconds) in the latest rest-client(1.8) gem which was being used in the newer Rails version. We added a smaller timeout to solve this issue. Because of this issue, some hive commands were taking a long time to complete.
One of the toughest parts of the Rails upgrade process was to follow up with QAs from different teams for the verification of regressions and then subsequently fix the bugs encountered on the same day so that we are on time.
Some points before you start your rails upgrade journey
The issue with Rails upgrade work is that it’s not the typical kind of work you’re used to.
Below are some of the points which make this task a daunting one:
- You won’t get the QA team’s help until you have upgraded the app to a working state. You have to depend more on Dev verification rather than QA verification.
- There are problems that only you will face as the codebase is entirely yours. So expect no help from StackOverflow on it.
- You need to have good knowledge of Ruby and Rails to debug some intricate issues and may still have a lot of uncertainty.
- This is a fast-moving project but not a project that you may finish in 2-3 months (depending on the project size). So it’s kind of a marathon where you have to sprint.
- Some breakages will happen in internal envs where the code gets merged and you have to be on top to solve any issue which may be caused by your change.
- You will need to understand the modules on which you have never worked and fix them to work on the newer Rails version.
- You need to have full knowledge of deployment (internal as well as production envs) so that you can plan your rollout in the best possible way.
- Have blue-green deployment if possible (EXPLAIN why)
Some things that are indispensable before you start the upgrade work:
- Have automation tests (Unit tests, integration tests, etc.) for everything and everywhere you can.
- Have an initial rollout plan with a rollback strategy
- Decide how you want to upgrade the Rails versions. We decided to move in a staggered approach.
- Have a target date to move fast (Github took 1.5 yrs to upgrade).
We deeply follow the following quote from Abraham Lincoln: “Give me six hours to chop down a tree and I will spend the first four sharpening the axe”.
How this upgrade affected us in a good way:
- We learned a lot about how to plan and break complex stories into smaller tasks, give better estimates, and execute tasks under tight deadlines without fail.
- We are better at managing time between different prioritized tasks.
- Our debugging skills improved in a significant way. We are now involved with other teams for application issues which helped a lot in gaining visibility across teams.
- Since we had to plan rollout capturing all the corner cases, we understand the nuances of a release rollout more than ever.



