Welcome New Generation Instance Types
Amazon Web Services (AWS) offers a range of instance types for supporting compute-intensive workloads. The compute-optimized instance family has a higher ratio of compute power to memory. The older generation C1 and CC2 instance types have been beneficial in batch data processing frameworks such as Hadoop.
Late last year Amazon Web Services (AWS) introduced a new generation of compute-optimized EC2 instances. The table below illustrates the comparison between instance types from older and newer generations with comparable configurations.
Learn how to Significantly reduce costs in AWS using Spot Instances
| Instance Type | vCPU | ECU* | Memory(GiB) | Instance Storage (GB) | Price |
| c1.xlarge | 8 | 20 | 7 | 4 x 420 | $0.520 per Hour |
| c3.2xlarge (new generation) | 8 | 28 | 15 | 2 x 80 SSD | $0.420 per Hour |
* ECU is an EC2 Compute Unit that provides the relative measure of the integer processing power of an Amazon EC2 instance.
The new generation c3.2xlarge has a clear edge over the c1.xlarge instance type:
- 40% better performance in terms of EC2 compute units
- 19% cheaper
- 2x the memory
- SSD storage
- Supports enhanced networking capabilities in a VPC
Hadoop and New Generation Instance Types
Terasort Performance
To get a better idea about the new instance types’ performance using the Hadoop framework, we ran the Hadoop Terasort benchmark on sample data and compared the runtime for sorting 100GB of data with a block size set to 512M. We observed a 30-50 percent improvement using c3.2xlarge (new generation) compared to c1.xlarge (old generation). The improvements are in the expected range as suggested by ECU improvement.
The Dark Side – Low Storage Capacity
However, one place where the C3 instance family lacks is the low local data storage capacity compared to the previous generation. For example, c1.xlarge has 1.6 TB of instance storage compared to only 160 GB available on c3.xlarge, or 640 GB on the high-end expensive c3.8xlarge instance.
Instance Type Instance Storage (GB) c1.xlarge 1680 [4 x 420] c3.2xlarge 320 [2 x 160 SSD] c3.4xlarge 320 [2 x 160 SSD] c3.8xlarge 640 [2 x 320 SSD]
The amount of storage per instance might not be sufficient for running Hadoop clusters with high volumes of data.
The issue with Low Instance Storage
Hadoop extensively uses instance storage for important features such as caching, fault tolerance, and storage. Distributed file system component of Hadoop, HDFS, relies on local storage across participating instances to store replicas of data blocks. MapReduce framework uses a local file system for storing intermediate map outputs, spill files, distributed cache, etc., which can result in high volumes of disk usage while working with reasonably sized datasets.
The lack of storage space on C3 instances can make them unusable for jobs that need to process large chunks of data. The Addition of more nodes – only for storage – will reduce the cost benefits this class of instances offers.
Elastic Block Storage (EBS) – Why and Why Not?
AWS offers raw block devices called EBS volumes which can be attached to EC2 instances. It is possible to attach multiple EBS volumes with a size of up to 1 TB per volume. This can easily compensate for the low instance storage available on the new generation instances. Also, the use of EBS volumes for storage purposes costs much less than adding cheaper instances with more storage capacity.
However, EBS comes with its own set of disadvantages. Magnetic EBS volumes provide bursty performance with around 100 IOPS on average which is significantly slower than SSD drives. Hadoop uses the available disks in a JBOD configuration and if EBS volumes were to participate in all operations, the performance will be highly degraded since all configured disks are used in a round-robin fashion.
EBS has also been at the centre of AWS cloud outages which makes it less of a preferred candidate for heavy usage
(https://aws.amazon.com/message/65648/, https://aws.amazon.com/message/680342/, https://aws.amazon.com/message/2329B7/, https://www.theregister.co.uk/2013/08/26/amazon_ebs_cloud_problems/).
In addition to the performance impact and availability, there is an additional cost associated with I/O performed on EBS volumes. A million I/O requests to a magnetic volume cost only a few cents but a large number of requests over time in the cluster can result in unnecessary costs.
Introducing Reserved Disks
We have introduced the notion of reserved disks within our stack. The idea is to have a disk hierarchy where faster disks on an instance get prioritized over slower disks. The reserved disks are used only when the storage requirements cannot be satisfied by existing disks on the instance. In our case, the SSD disks will be used for regular functioning and the mounted EBS volumes will act as reserved disks.
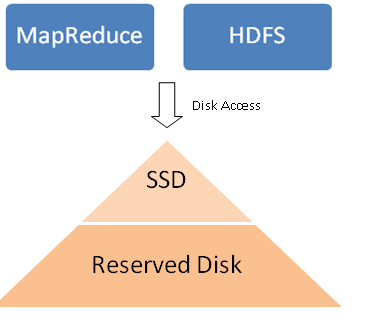
Reserved Disks and MapReduce (MR) Requirements
Various contexts within the MR framework need to be read and write to local disk storage. A common example is the list of directories specified using mapred.local.dir configuration which is used for storing intermediate data files. The configuration value contains directories residing on low latency and high throughput SSD volumes.
On instances with low local storage, an additional configuration property (local.reserved.dir) can be set to contain a list of directories residing on mounted EBS volumes. These directories are accessed only if the request to read, write or existence check could not be served from the regular volumes. The above arrangement ensures that if there were sufficient space on fast (SSD in our case) volumes, then the high latency EBS volumes are not used.
Additionally, once a job completes, the intermediate data associated with it is cleaned up making the SSD volumes available for other jobs. This reduces access to reserved volumes.
The reserved disks are used in a round-robin scheme for allocation. The last reserved disk on which a file write operation was performed is tracked. The subsequent write request is catered by the next disk in the list having sufficient capacity. This ensures that tasks on the same instance are distributed across volumes and a single volume does not become a bottleneck. The scheme used is similar to the one used by the local directory allocation mechanism within Hadoop (LocalDirAllocator).
Reserved Disks and HDFS
Similar to the above approach, HDFS can be configured to use reserved volumes using the configuration parameter dfs.reserved.dir. The volumes so specified are marked as reserved. The target node selected for placing a block replica uses the reserved disk/EBS volume only if there is insufficient space on disks specified using dfs.data.dir.
The reserved volumes for HDFS follow the regular round-robin scheme. In both cases, it is ensured that a reserved volume is used only if it is healthy.
Auto-scaling Clusters and Reserved Disks
Qubole Hadoop clusters auto-scale based on workload. Since Hadoop workloads generally have uneven spikes, the clusters witness up-scaling and down-scaling activity. As soon as the instance is added to the cluster, the reserved volumes are automatically mounted to the instance and are ready to use. To save additional costs, we plan to delay this process till the disk utilization on the node crosses a certain threshold. When the cluster downscales, the instances within the cluster are terminated. The termination process automatically removes and terminates the EBS volumes mounted (if any) on the instance. As a result, during low load, the cluster runs with a minimum number of instances and hence with a lower number of EBS volumes.
Configurable Reserved Volumes
On the Qubole platform, using new generation instances, users have the option to use reserved volumes if the data requirement exceeds the local storage available in the cluster.
AWS EBS volumes come in various flavors e.g. magnetic, SSD backed. Users can select the size and type of EBS volumes based on the data and performance requirements.
Reserved Volume Cost Analysis
For a node in a cluster with 100GB EBS reserved volume, the static cost of using reserved volume will be around 17₵ ($0.17) per day. This amounts to less than 2% of the daily cost of c3.2xlarge instances and will be lower for other instances in the family such as c3.4xlarge (0.8%) and c3.8xlarge (0.4%).
The only additional cost is for the I/O operations performed on these volumes which will be proportional to the amount of data stored in the cluster in addition to local instance storage. The additional requests are reasonably priced at $0.05 per 1 million I/O requests.
Conclusion
Using the reserved volume technique with new generation instances, it is possible to achieve 50% better performance for Hadoop jobs with an approximately 17% reduction in costs. Better performance at a lower cost!



