We are pleased to announce the availability of Apache Spark 3.0 in the Qubole environment.
Spark 3.0 release comes with a lot of exciting new features and enhancements. Some of the key highlights of the new release are Adaptive Query Execution, Dynamic Partition Pruning, and Disk-persisted RDD blocks served by shuffle service. There are also significant improvements in pandas API and up to 40X speedups in invoking R user-defined functions. Scala 2.12 is Generally Available while Scala 2.11 is removed in the latest version.
On top of the open-source release, we have added over 700 patches to provide various value-added capabilities for our customers. These features are already available with Spark 2.4 version on the Qubole platform and now they can be used with Spark 3.0 clusters as well
In the following sections, we will dive deeper into some of the supported functionality
Adaptive Query Execution
Adaptive Query Execution (AQE) changes the Spark execution plan at runtime based on the statistics available from intermediate data generated and stage runs. The optimized plan can convert a sort-merge join to broadcast join, optimize the reducer count, and/or handle data skew during the join operation.

Configuration property:
| spark.sql.adaptive.enabled | Disabled by default |
Dynamic Partition Pruning
Dynamic Partition Pruning (DPP) optimization improves the job performance for the queries where the join condition is on the partitioned column by selecting the specific partitions within the table that need to be read at runtime. This is the amount of data read and processed.
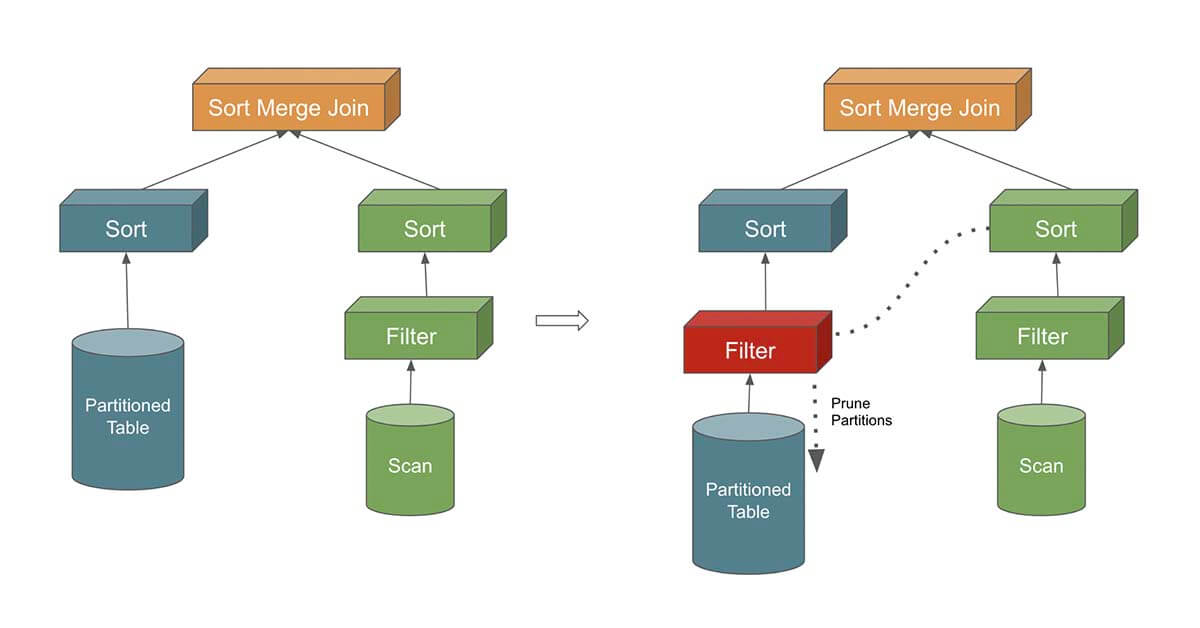
Configuration:
| spark.sql.optimizer.dynamicPartitionPruning.enabled | Disabled by default |
Dynamic Partition Pruning implementation in Open Source is disabled by default in favor of Dynamic Filtering that was introduced by Qubole as it covers both Dynamic Row filtering and Dynamic Partition Pruning and is generally available from Spark 2.4 onwards.
New Optimizer rules in Spark SQL
Spark SQL module, which is core to higher-level APIs and libraries such as MLlib, Structured streaming, and Data Frames, has a majority of new changes in the latest Spark version. Apart from AQE and DPP discussed above, multiple optimizer rules are added to the Spark catalyst optimizer. These rules optimize queries written in SQL or in data frame APIs and improve performance without changing user code. Notable new rules to leverage are
- Subqueries reuse – In Spark all the subqueries are executed completely before the execution of the actual query starts. This rule adds the reuse of subquery to prevent the execution of the same subquery again.
- Hive table partition pruning – Earlier, metastore statistics were used to return the size of the entire table and the plan could suboptimally choose sort-merge join over the broadcast join. After this change, pruned partitions are taken into account for the Hive table using “plan.stats.sizeInBytes” and this improves performance by using broadcast join if possible.
- Push down filters in Left Semi Anti join, and Left Semi Anti Through Join – This rule, which is a variant of PushPredicateThroughJoin, handles pushing down of Left Semi and Left Anti joins below a join operator. Most of the predicates can now be pushed down for cascading joins such as Filter-Join-Join-Join and thereby improving the query performance.
- Eliminate sorts without limit in the subquery of Join/Aggregation – This rule avoids unnecessary sort operations in the subquery of a join/aggregation operation without any limit operator. This improves the overall performance of the query execution.
The complete list of new optimizer rules here
Disk-persisted RDD Block Served by Shuffle Service
Spark introduced the Disk-persisted RDD blocks served by shuffle service. There are scenarios where the executors are not downscaled even if the executors are idle for a long time. This is due to the RDD Cache present on those executors. Also, Cached RDD blocks will be unavailable after an executor is removed, resulting in recomputing of the RDD again by some other executors. After this change fetching of RDD will work in the same manner as it’s working for Shuttle data using Shuffle Service. Now the executors are not responsible for maintaining the state of RDD and can downscale easily. This change optimizes the dynamic allocation of resources in Spark.
Configuration:
| spark.shuffle.service.fetch.rdd.enabled | Disabled by default |
Qubole Supported Features in Spark 3.0
Qubole provides the best of both worlds – new functionalities of OSS releases and various custom changes. It is the most performant, open, and secure data lake platform. Additional benefits of Qubole in Spark 3.0 are
Total Cost of Ownership (TCO)
- Qubole Stage Level Optimized Autoscaling – Get the best underlying resource utilization with stage-level autoscaling. Details can be found here.
- Handling Graceful Decommission – Optimize the jobs for lower costs while minimizing the job loss in the spark cluster on Qubole with Intelligent Spot management. Details can be found here.
- Workload Packing for Spark Cluster – Workload Packing is a new resource allocation strategy that makes more nodes available for downscaling in an elastic computing environment, while at the same time preventing hot spots in the cluster and honoring data locality preferences. More details can be found here
Write Optimizations
- Direct Writes in Storage – A Spark optimization that delivers performance improvements of up to 40x for write-heavy Spark workloads(Must read details are available here)
- Distributed Writes – Qubole provides both API/UI interfaces to execute spark SQL queries. The results of the query are collected on Spark’s driver-caused memory and performance issues. Distributed writes directly save the results in the cloud’s object store from the Spark executors during the execution of the query.
Read Optimizations
- Dynamic Filtering in Spark – The distributed SQL engine in Apache Spark on Qubole uses a variety of algorithms to improve join performance. Dynamic Filtering in Spark with Qubole dramatically improves the performance of Join Queries. It covers both Row filtering and Partition Pruning at runtime.
- Skew Join Optimization – Spark optimization to handle Skew in Joins, by providing provision for users to specify hints. Users can specify the hints for join specifying the join keys that are skewed and the values they are skewed upon. Based on the hint provided, the engine automatically takes care of skewed values.
Data Governance for SparkSQL
- Apache Ranger – Users can do fine-grained data access control, including row-level filtering, and column-level masking. Qubole supports Apache Ranger with Spark. More details can be found here.
- Hive Authorization – Users have the ability to control granular access to Hive tables and columns as Qubole supports Hive authorization. This is especially beneficial with Hive-based metastore. Details can be found here.
Usability & Reliability enhancements
- Memory Pressure Based Scheduling – At Qubole, we have observed that many Spark applications experience failures because of repeated Out of Memory (OOM) exceptions, even with carefully tuned configuration values. We have worked on task management that gracefully handles memory pressure in executors. It dynamically adapts the task scheduling to ensure better reliability. This functionality is available with version Spark 2.4 and above on the Qubole platform.
- Spark History Server – Spark History Server robustness and performance improvements can be experienced with:
- LevelDB-based EventLog Store to render Spark UI for long-running Spark applications.
- Persistent Spark History Server for ephemeral clusters on the cloud.
- Garbage collection and heap information for all the executors under the Executors Tab
Streaming Analytics
- Qubole Pipelines Service – A stream processing service that complements your data lake with advanced capabilities to help one quickly ingest and process not only streaming data but also can combine with batch data from various sources. It accelerates the development of streaming applications and increases business insight precisions. Further, users can run highly reliable and observable production applications in a managed environment at the lowest cost. More details can be found here
Getting Started With Spark 3.0.0 On Qubole
Launch a cluster with Spark 3.0.0 just like any other supported Spark versions in Qubole and get going
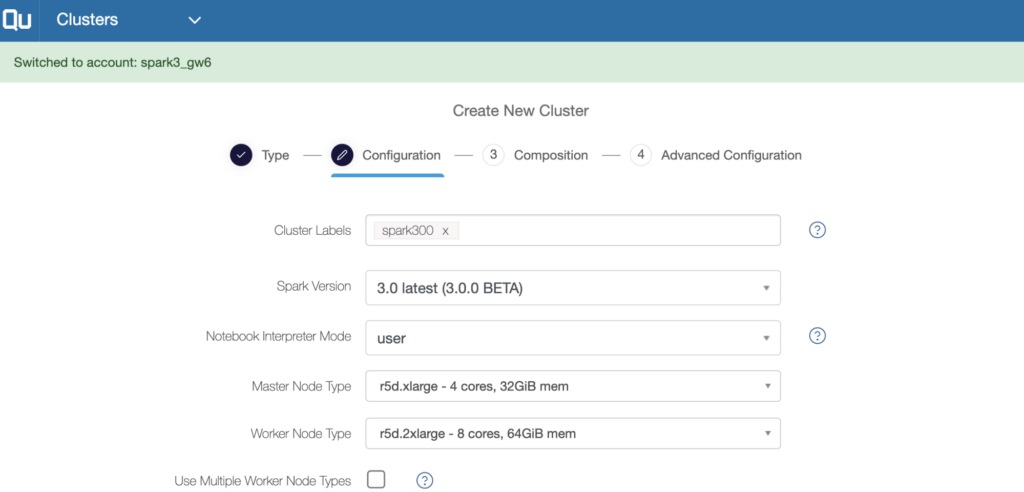
Figure 1 Shows Creating the Spark 3 clusters in Qubole
Support Matrix
- Default Hive built-in version is Hive 2.3. If you are using a self-managed Hive metastore and are on an older metastore version (Hive 1.2), few metastore operations from Spark applications can fail. You may want to upgrade the metastores to Hive 2.3 or above. For QDS-managed metastore, it has already been upgraded for you.
- Spark 3.0 can be used using workbench, Jupyter, and Apache Zeppelin notebooks.
- In Spark 3.0 the default version of Scala is 2.12. We recommend building any Spark job with Scala 2.12 before running it on the Spark 3.0.0 cluster.
- Spark 3.0 is supported with Hadoop 2.x.
Upcoming Features
Below is the list of features that are not currently supported in Spark 3.0
- Redshift Datasource to read from and write into Redshift
- Spark Data Source for Hive ACID tables
- Support of Hadoop 3
- S3 Select integration which helps in performance optimization by converting Hive/data source table to S3 Select and pushing down projects/filters for CSV and JSON file formats.
Upgrading from Spark 2.4.x to Spark 3.0.0
Please follow this link for the migration of the Spark Application from Spark 2.4.x to Spark 3.0. Some of the notable migration steps are
- Any message on the stderr channel from pyspark program will be redirected to the Logs tab of the analyze/workbench UI. Earlier all such errors were redirected to the Results Tab
- yarn-client and yarn-cluster modes were deprecated in previous Spark versions and have now been removed in Spark 3.0. One needs to use –master=yarn and specify –deploy-mode option with the spark-submit command-line arguments.
- The deprecated HiveContext class has been removed. One needs to use SparkSession.builder.enableHiveSupport() instead of it.
- The configuration `spark.sql.crossJoin.enabled` has become an internal configuration, which is true by default. Spark will not raise an exception on SQL query with an implicit cross join.
- Since Spark 3.0, the order of argument is reversed in the TRIM method. One needs to change TRIM(trimStr, str) to TRIM(str, trimStr).
- Due to the upgrade to Scala 2.12, DataStreamWriter.foreachBatch is not a source compatible with the Scala program. You need to update your Scala source code to disambiguate between the Scala function and Java lambda.
For further details, refer to the Qubole documentation on Apache Spark here. If you don’t yet have a Qubole environment, you can try Spark 3.0.0 by signing up for a free 14-day Qubole free trial.



