Data Lakes are becoming increasingly central to the analytical operations of organizations. This brings in many more ‘transactional’ requirements on the pipeline architecture and the data lake design itself. Consumer privacy laws like GDPR, CCPA, and PDP bring in more requirements that challenge the traditional designs of the data lake. Check out the first and second parts of this blog series, which discuss common design patterns of ingestion and tuning ingestion processes, respectively.
In this part of the blog series, we will see how to perform ‘Transactions’ on the data lake, which allows RDBMS like Inserts, Updates, and Deletes on data lakes. We will discuss the pros, the cons, and the best practices to make the most of this capability.
If you are coming from an RDBMS background, you will know the ‘ACID’ concept very well. Here is a quick refresher:
- Atomicity: A transaction should either complete successfully or just fail. There should not be any partial success.
- Consistency: A transaction will bring the database from one valid state to another state.
- Isolation: Every transaction should be independent of each other i.e., one transaction should not affect another.
- Durability: If a transaction is completed, it should be preserved in the database even if the machine state is lost or a system failure might occur.
These principles will be very much applicable in the data lake as well if you have concurrent Read or Write use cases.
The challenge of concurrent reads and writes
There are different ingestion tools like Kafka, Sqoop, and Spark, which can add data into Data Lake at different speeds. While these tools can write data at rates of hundreds or more rows per second, Hive can only add partitions every fifteen minutes to an hour. Adding partitions more often leads quickly to an overwhelming number of partitions in the table. These tools could stream data into existing partitions, but this would cause readers to get dirty reads and leave many small files in their directories.
These two challenges can be handled by ACID functionality. There are many use cases possible where we would be facing dirty reads (jobs failure in some cases) and small file issues.
Use cases
Streaming Ingestion of Data
If data is coming in via some streaming pipeline and we want to update the destination table at regular intervals then hive ACID can be useful.
Slow changing dimensions
In a typical star schema data warehouse, dimension tables change slowly over time. For example – In a gaming company, one user was registered last year, and now he just updated some personal info, and the changes need to be reflected in the data lake.
Data restatement
Sometimes collected data is found to be incorrect and needs correction. With Hive ACID, one can easily update specific records.
Bulk updates
Merge commands are supported. Any transactional data which is coming as part of the CDC pipeline can be merged with the historical data.
Insert/Update/Delete
GDPR, CCPA provides guarantees like the Right to Erasure or the Right to be forgotten. With Hive ACID, we can easily delete the PII of a few users from within billions of records.
How does Hive ACID work?
In a nutshell, Hive ACID works by maintaining subdirectories to store different versions and update or delete changes for a table. The Hive metastore is used to track the different versions. To get rid of too many subdirectories, Manual and Automated Compaction processes are there, which just merge those delta files.
Refer to this link here for a deep dive into how Hive ACID works.
Qubole’s enhancements
Multi-engine Compatibility
Qubole supports best-of-breed data processing engines and frameworks for end-to-end data processing. ACID functionality is available across all the available engines. Users can leverage Spark or Hive engines for the WRITE operations and to read the data from any ACID table all three supported engines Spark, Hive, Presto can be used.
Supported File Format
ORC and Parquet file formats are the most commonly used formats, and ACID support is there for both in Qubole.
MERGE command
Spark and Hive can be used for running MERGE commands in Qubole.
Direct write
Direct write optimization is supported for both INSERTS and COMPACTIONS processes. Here, we don’t write to the intermediate locations and hence get better performance.
BlobStore commit marker
This is to avoid reading partially written data.
Working with Hive ACID
Scenario
Let us look at the capabilities and functionalities of Hive ACID with an example. In our example, we are setting up our Data Lake to maintain data about the COVID-19 pandemic. We are capturing statistics like total cases, recoveries, and fatalities per country-state combination.
Our final analytical table is the ‘covid_snapshot’ table. This will contain the latest COVID-19 statistics for each country-state combination.
Our change data is being staged in a delta table called ‘covid_delta’. This will contain all the statistics updates received from our source system. This means there could be multiple entries for the same country-state combinations. Depending on our use case, we might need all the entries or just the latest one.
Creating Tables
Create a fully transactional table. Here, we are creating a fully transactional table named ‘covid_snapshot’. The level of transactionality is defined by the property ‘transactional = true’. The other option is ‘insert-only’ which disallows Delete operations.
CREATE TABLE `covid_snapshot`(
`sno` int,
`observation_date` string,
`state` string,
`country` string,
`last_update` string,
`confirmed` double,
`deaths` double,
`recovered` double)
STORED AS ORC
TBLPROPERTIES ('transactional'='true');
Inserts, Updates & Deletes
Once we have a transactional table, we can perform transactional operations like INSERT, UPDATE, and DELETE. This is useful when we want to process a few records. In the following examples, we are performing some transactional statements on the table that we created.
INSERT INTO covid_snapshot VALUES(50001, "06/20/2020", "Miyazaki", "Japan", "2020-06-21 04:33:19", 100, 50, 25); UPDATE covid_snapshot SET confirmed=105 WHERE sno=50001; DELETE FROM covid_snapshot WHERE sno=50001;
Bulk Merges
In the previous example, we were processing a limited set of records. However, it is common practice to hold CDC data(Inserts, Updates, and Deletes) in a delta(staging) table and then update the destination table at some cadence. This can be done to avoid unnecessary reprocessing when real-time synchronization is not required.
In such a case we can use Hive ACID’s MERGE capabilities to apply the CDC to the destination table in bulk and very efficiently.
We have a delta covid_delta table, which is getting generated as part of our CDC pipeline. We would want to merge these changes into our final snapshot table. We can state the requirements as
- We would like to have a unique combination of country and state in our snapshot table
- We would like to have the latest observation_date record for the combination after the merge operation
SET tez.grouping.by-count=true; SET tez.grouping.split-count=100; MERGE INTO covid_snapshot AS h USING (SELECT tmp.sno, tmp.observation_date, tmp.state, tmp.country, tmp.last_update, tmp.confirmed, tmp.deaths, tmp.recovered FROM (SELECT sno, observation_date, state, country, last_update, confirmed, deaths, recovered, Row_number () OVER ( partition BY state, country ORDER BY observation_date DESC ) AS rno FROM covid_delta) AS tmp WHERE tmp.rno = 1) AS d ON h.country = d.country AND h.state = d.state WHEN matched AND ( h.confirmed != d.confirmed ) THEN UPDATE SET confirmed = d.confirmed, deaths = d.deaths, recovered = d.recovered, observation_date = d.observation_date, last_update = d.observation_date WHEN NOT matched THEN INSERT VALUES ( d.sno, d.observation_date, d.state, d.country, d.last_update, d.confirmed, d.deaths, d.recovered );
Note: In MERGE operation, the delta table should have unique combinations of the used keys (state and country).
Compactions
Frequent insert/update/delete operations on a table/partition create many small delta directories and files. This can cause performance degradation over time. Compaction at regular intervals can alleviate this problem.
- Minor compaction takes a set of existing delta files and rewrites them to a single delta file per bucket.
- Major compaction takes one or more delta files and the base file for the bucket and rewrites them into a new base file per bucket. Major compaction is more expensive but is more effective.
Hive ACID v2 supports both manual and automatic compaction via HMS and this compaction runs as a Hadoop job (MR or Tez). Details about the compaction can be found here.
Here is an example of triggering compaction manually
SET hive.compactor.worker.threads=2; SET hive.compactor.delta.num.threshold=2; SET hive.compactor.delta.pct.threshold=0.1f; ALTER TABLE covid_snapshot compact 'major';
Directory structure BEFORE compaction –
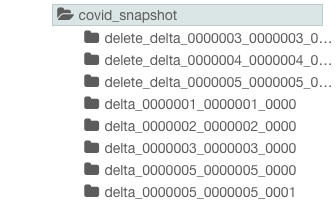
Directory structure AFTER compaction –

Numbers from the field
We would like to share some numbers from the field –
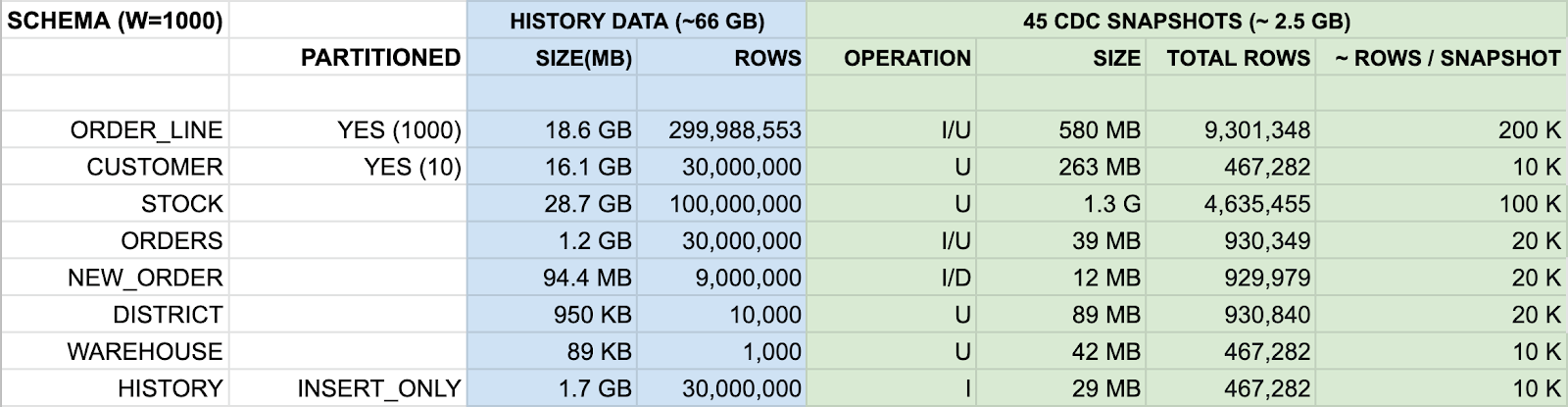
There are eight tables that are getting inserts/updates/deletes frequently in the transactional system MySQL, and the changes are coming into S3 via ingestion pipeline (AWS DMS + Kafka + Qubole Pipelines Service)
Here, the table below shows 45 iterations of MERGE commands against the change data coming from the pipeline, and it took around ~4 hours to complete all of those commands. MERGE commands were running in parallel for all of the tables, and most of the smaller tables completed their iterations in very little time, but the bigger tables took up to four hours to finish all of the iterations.
Total Number of MERGE commands = 45 * 8 = 360
Cluster Configuration
- Main Cluster:
- Master – r5.2xlarge
- Worker – r5.4xlarge (Min 1, Max 3 nodes)
- Compaction Cluster:
- Master – r5.xlarge
- Worker – r5.2xlarge (Min 1, Max 2 nodes)
Disclaimer
This is just a sample number from one of our customer’s workloads. We’ll be publishing a very detailed engineering blog on the ACID benchmarking very soon.



