Introduction
Enterprises are today becoming more data-driven as their data is the fuel to their innovation engine to build new products, outmaneuver the competition and provide customers better experiences. As a result, big data management and processing for various stakeholders such as Data Analysts, Data Engineers, and Data Operations organizations should be fast, automated, and scalable.
Four common reasons for unpredictable unexpected bills
Enterprises doing multiple projects with big data use public cloud services for compute and storage. The public cloud provides agility and scale to execute these projects within a few clicks and broadly match supply with demand. Further, the cloud lets enterprises build and run the best breed big data processing systems. The services offered are all on-demand, pay-as-you-go services, therefore, letting ad-hoc analysis, and POCs driven by big data start easily and without any huge upfront bills. Over time as projects mature or ad hoc queries become longer, the seemingly endless supply of underlying resources leads to wasteful expenditure on compute and resources and very little accountability, guesstimate show back. The usage comes with cost unpredictability and lacks financial governance. This is associated with the following:
Long-Running Servers
Most application requests are driven by external clients which are not known in advance. As a result, the servers are kept in anticipation of these requests.
Performance Optimization
Typical web applications, serving external requests, are optimized to reduce latency rather than cost. As a result, the servers are provisioned well in advance, rather than on-demand and not tuned to adapt to changing workloads.


Figure 1: Qubole Credit Units Consumption Trends on Monthly, Hourly, and Daily Basis
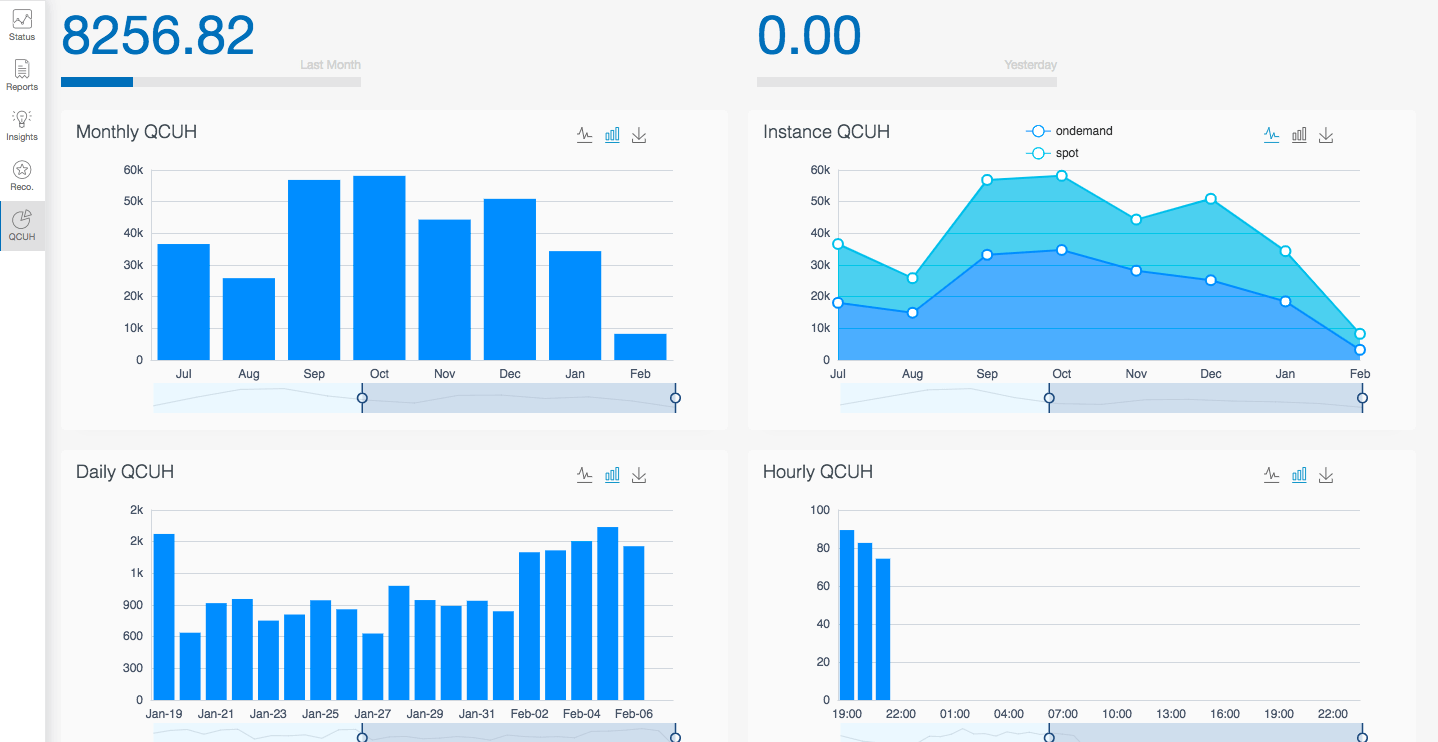
Uniform Load Increase vs Burstiness
Most web applications’ underlying requirements are built on the assumption of a uniform increase and decrease of workload gradually over a period of time instead of an acute increase or tail-end decrease of resource consumption. For example, the burstiness of workloads spawning thousands of parallel tasks requires 1000’s servers/machines for a short duration of time not planned earlier. It also cannot be micromanaged to keep financial checks and balances.
Idle Period
Unlike web applications that have a steady flow of traffic 24/7 big data workloads can be scattered during a given day, leading to several blocks of the idle time period when there are no workloads.
Best practices to have financial governance on an ongoing basis
Data-driven enterprises nowadays face financial governance challenges on a regular basis as the number of big data projects using the public cloud internally has risen exponentially. Whilst traceability and predictability are important elements in financial governance policies, cost control, and expense reduction are usually the starting focus of any financial governance exercise. Enterprises take the following steps to bring financial governance:
Optimize for Performance
Enterprises optimize for performance which not only accounts for the speed of query execution but also considers the timeliness of the execution.
Prioritize Capacity Management as an ongoing exercise
Capacity management in the cloud is now about infrastructure utilization optimization with financial governance guard rails for teams to not only move fast on their projects but also not to worry about unexpected bills. The organization’s goal during the optimization is to build systems that constantly provide sufficient capacity to be slightly above that needed while maintaining the traceability and predictability of user, cluster, and job cost metrics levels. Organizations are doing the following:
- Remove orphaned or unused infrastructure
Remove infrastructure that was left behind when another infrastructure was terminated (eg disk volumes, ideally combined with auto-snapshot before deletion) or infrastructure that sits idle for a specified amount of time. - Resize under-utilized infrastructure
Adjusts the size of infrastructure that has spare resources to an appropriate level. This requires careful policy creation as capacity has to take into account expected spikes in usage. - Lifecycle management of infrastructure based on schedules
Automate the creation and destruction of systems to fit around usage patterns. For example, create development environments for use during office hours or extend production platforms during peak trading hours. - Cost Optimize with a heterogeneous environment
Apply tooling generally DIY scripts to automate system management to use infrastructure with the best value whilst meeting the levels of resilience and availability required by the system. - Limited Traceability Management
Apply rules at a cluster, cluster-instance, user, and job level to ensure policies are configured automatically to destroy any elements that are created that do not meet the tagging policy in place.

Figure 2: User-based Breakdown of Resource Consumption
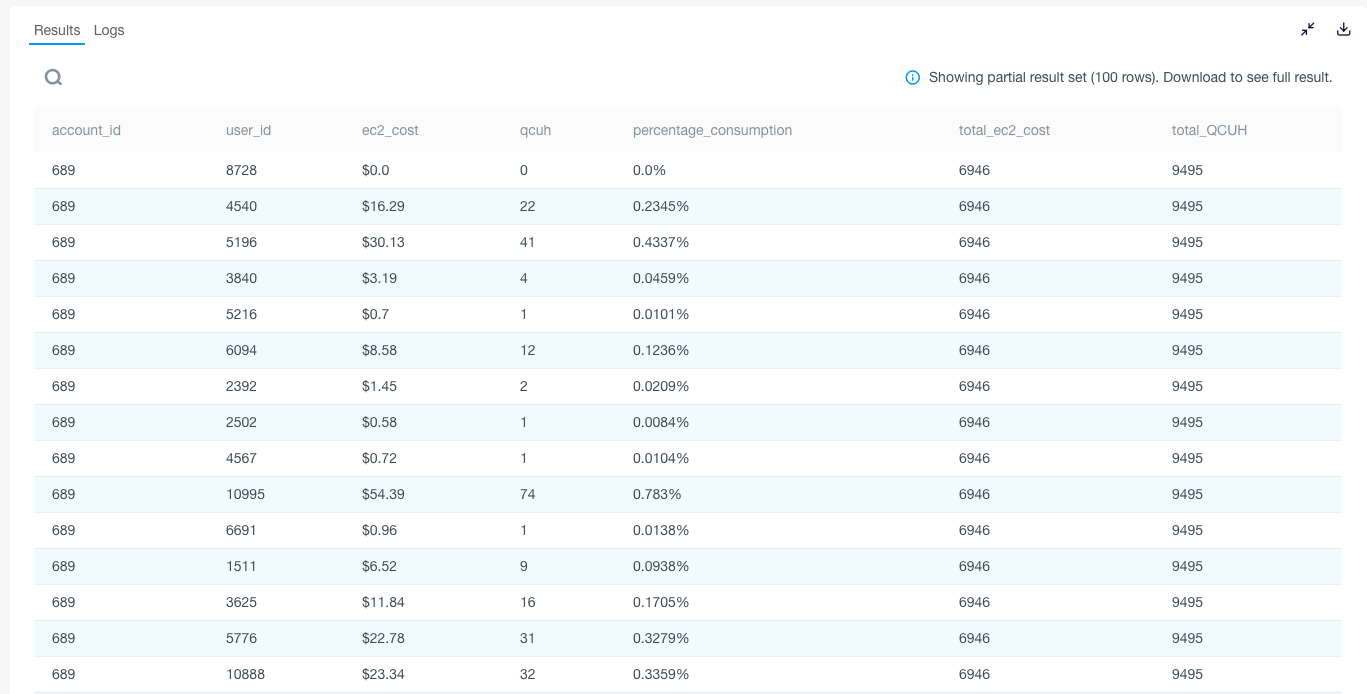
Adopting Data Platform with built-in Financial Governance Metrics
Enterprises now leverage platforms such as data platforms to drive financial governance within the organization to reduce operating costs, do an ROI analysis, have showback discussions,s and identify to spend assets. In addition to cluster lifecycle management, Qubole data services offer Workload Aware Autoscaling to strengthen the financial governance within an organization as multiple teams run big data in a shared cloud environment or separate ones which can be combined to deliver more savings without compromising performance:
Cost Explorer
Cost explorer provides user, job, and cluster-level cost metrics in a shared environment to provide data-driven show-back information for a fact-based discussion in the enterprise.

Figure 3: Cost Reporting with Qubole
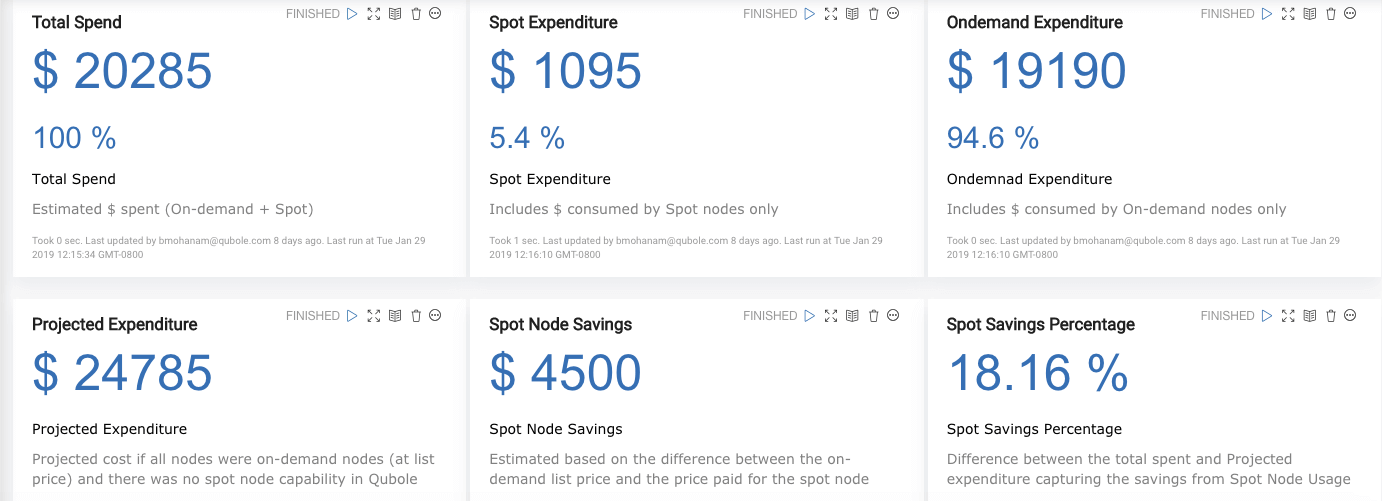
Optimized Upscaling
Optimized Upscaling reclaims unused resources from the running containers in the cluster and allocates them to the pending containers. This improves the cluster throughput and reduces the delays due to provisioning machines while lowering the TCO and cost avoidance.
Aggressive Downscaling
Aggressive downscaling prevents cost overruns after the job is completed by shutting down idle nodes, rebalancing workloads across active nodes, and decommissioning idle ones without the risk of data loss.
Container Packing
Container Packing, a resource allocation strategy, makes more nodes available for downscaling in an elastic computing environment, while at the same time preventing hot spots in the cluster and honoring data locality preferences.
Diversified Spot
Qubole automatically provisions nodes from different Ec2 Instance types, to maximize the number of instances fulfilled by the cloud provider. Diversifying the instance types reduces the chances of bulk interruption of Spot nodes by Cloud Provider. When a spot node of one particular instance type is not available, Qubole automatically tries other instance types rather than falling back to on-demand.
Managed Spot Block
While Spot Block instances provide reliability for a finite duration(1-6 hours), AWS will recall these nodes after that duration leading to node loss(failure). To prevent this failure from impacting cluster operations or workloads, Qubole has built-in Intelligent Spot Block Management features that provide: Risk Mitigation, Impact Mitigation, and Fault Tolerance and ensures cluster operations can continue, without failure, beyond the finite duration of the spot block.
Summary
Enterprises can now leverage Qubole cloud-native data platform’s cost avoidance and TCO optimization features to have data-driven user, job, cluster, or cluster-instance level cost metrics discussions to measure ROI on their big data projects.



