NEW! Spark 3.3 is now available on Qubole. Qubole’s multi-engine data lake fuses ease of use with cost-savings. Now powered by Spark 3.3, it’s faster and more scalable than ever.
This is Part 2 of 3
Snowflake Spark Connector
Snowflake and Qubole have partnered to bring a new level of integrated product capabilities that make it easier and faster to build and deploy Machine Learning (ML) and Artificial Intelligence (AI) models in Apache Spark using data stored in Snowflake and big data sources.
In this second blog of three, we cover how to perform advanced data preparation with Apache Spark to create refined data sets and write the results to Snowflake, thereby enabling new analytic use cases.
The blog series covers the use cases directly served by the Qubole–Snowflake integration. The first blog discussed how to get started with ML in Apache Spark using data stored in Snowflake. Blogs two and three covers how data engineers can use Qubole to read and write data in Snowflake, including advanced data preparation, such as data wrangling, data augmentation, and advanced ETL to refine existing Snowflake data sets.
Transform Snowflake Data with Apache Spark
Snowflake stores structured and semi-structured data, which allows analysts to create new views and materialized views using SQL-based transformations like filtering, joining, aggregation, etc. However, there are cases where business users need to derive new data sets that require advanced data preparation techniques such as data augmentation, data wrangling, data meshing, data fusion, etc.
In these cases, the data engineer—and not the analyst—is responsible for the task, and benefit from a cluster computing framework with in-memory primitives like Apache Spark that make the advanced data preparation process easier and faster. In addition, data engineers need the flexibility to choose a programming language that best suits the task, such as object languages (Java), functional languages (Python or Scala), or statistical languages (R).
The Qubole–Snowflake integration allows data scientists and other users to:
- Leverage the scalability of the cloud. Both Snowflake and Qubole separate compute from storage, allowing organizations to scale up or down computing resources for data processing as needed. Qubole’s workload-aware autoscaling automatically determines the optimal size of the Apache Spark cluster based on the workload.
- Securely store connection credentials. When Snowflake is added as a Qubole data store, credentials are stored encrypted and they do not need to be exposed in plain text in Notebooks. This gives users access to reliably secure collaboration.
- Configure and start-up Apache Spark clusters hassle-free. The Snowflake Connector is preloaded with Qubole Apache Spark clusters, eliminating manual steps to bootstrap or load Snowflake JAR files into Apache Spark.
The figure below describes the workflow for using Qubole Apache Spark for advanced data preparation with data stored in Snowflake.
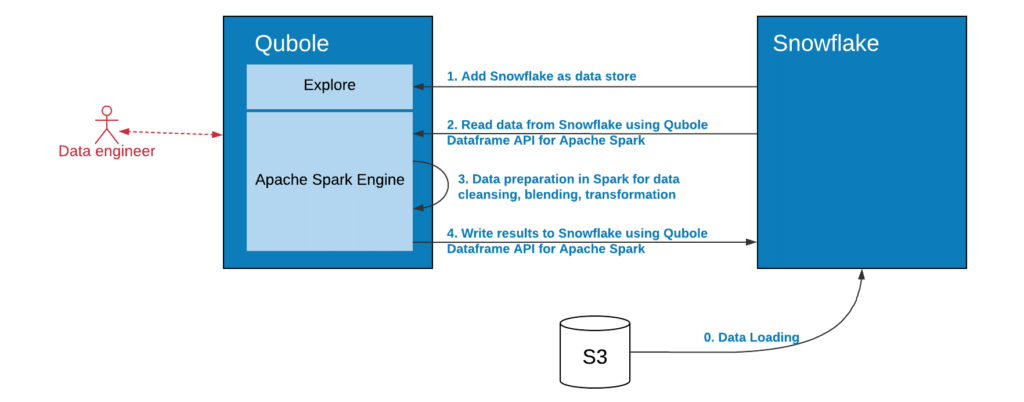
Load Data into Snowflake
The process starts by loading the data into Snowflake. Once that is complete, data engineers need to make the Snowflake virtual data warehouse visible to Qubole. Then data engineers can choose their preferred language to read data from Snowflake, perform advanced data preparation such as data augmentation, meshing, correlation, etc. and derive business-focused datasets that are then written back to either Snowflake or any other application, including dashboards, mobile apps, among others.
Snowflake Cloud Data Warehouse
The first step is to connect to a Snowflake Cloud Data Warehouse from the Qubole Data Service (QDS). We described the details of how to set up a Snowflake Data Store in the first blog of the series.
By adding Snowflake as a datastore in a QDS account, QDS will automatically include the Snowflake-Apache Spark Connector in each Apache Spark Cluster provisioned in this account.
Spark DataFrame
Once the Snowflake virtual data warehouse is defined as a Data Store you can use Zeppelin or Jupyter Notebooks with your preferred language (Java, Scala, Python, or R) to read and write data to Snowflake using QDS’s Dataframe API. Data engineers can also use the Dataframe API in QDS’ Analyze to accomplish this.
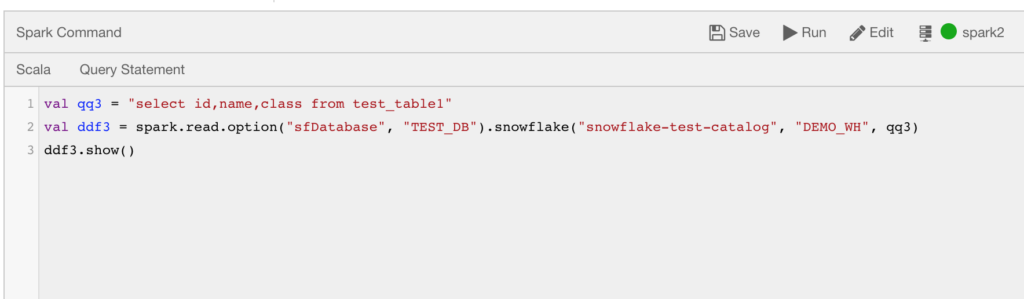
Below is a sample code in Scala to read data from Snowflake using the QDS Dataframe API.
val df = Spark.read
.option("sfDatabase","<database-name>")
.snowflake("<catalog-name>","<snowflake-virtual-warehouse-name>", "<query>")The screenshot below shows how to use the same code in the Analyze query composer interface.
Snowflake DataFrame
Once data is processed and a new data set is created, you can write the data to Snowflake using the same Data frame API interface, specifying in the last parameter the destination table name in Snowflake.
Below is a sample Scala code snippet to write data to Snowflake:
Df.write
.option("sfDatabase","<database-name>")
.snowflake("<catalog-name>","<snowflake-virtual-warehouse-name>", "<snowflake-table-name>")Snowflake Data Engineering
The integration between Qubole and Snowflake provides data engineers a secure and easy way to perform advanced preparation of data in Snowflake using Apache Spark on Qubole. Data teams can leverage the scalability and performance of the Apache Spark cluster computing framework to perform sophisticated data preparation tasks in the language that best suits their need (Java, Python, Scala, or R) very efficiently.
Qubole removes the manual steps needed to configure Apache Spark with Snowflake, making it more secure by storing encrypted user credentials, eliminating the need to expose them as plain text, and automatically managing and scaling clusters based on workloads.
For more information on Machine Learning in Qubole, visit the Qubole Blog. To learn more about Snowflake, visit the Snowflake Blog.



