Today, Qubole is announcing the availability of a working implementation of Apache Spark on AWS Lambda. This prototype has been able to show a successful scan of 1 TB of data and sort 100 GB of data from AWS Simple Storage Service (S3). The blog dives into the technical details of how we built this prototype and the code changes required on top of Apache Spark 2.1.0.
Motivation
AWS Lambda is a serverless compute service. It allows you to scale when needed while paying for only the compute used, and avoiding the need to provision servers. This allows applications to be highly elastic in terms of the compute demands and still run efficiently.
Apache Spark is a fast, general-purpose big data processing engine. It is growing in popularity due to the developer-friendly APIs, ability to run many different kinds of data processing tasks, and superior performance. The ability to run Apache Spark applications on AWS Lambda would, in theory, give all the advantages of Spark while allowing the Spark application to be a lot more elastic in its resource usage. We started the Spark On Lambda project to explore the viability of this idea.
Qubole implementation of Spark on AWS Lambda allows:
- Elasticity: We can now run bursty workloads that require thousands of Spark executors using AWS Lambda invocations – without waiting for machines to spin up.
- Simplicity: At Qubole, we run some of the largest auto-scaling Spark clusters in the cloud. The self-managing clusters have allowed democratization and widespread adoption of Big Data technologies. However, a Lambda-based implementation further simplifies configuration and management for administrators.
- Serverless: The popular ways of running Spark are using the Standalone mode or on Apache Hadoop’s YARN. These methods presuppose the existence of a cluster and the elasticity of these applications is limited by the underlying cluster’s ability to scale up and down. With Spark on Lambda – the concept of a cluster goes away entirely.
- Transparency: A Spark application invokes a number of AWS Lambda functions – each with a well-defined cost. This allows us to calculate, exactly, the cost of running each Spark workload.
Use Cases
Some of the common use cases that can be tackled using this combination include:
- Data pre-processing and preparation: Transformation of logs like clickstream and access logs for ETL or for Data Mining can be done using AWS Lambda.
- Interactive data analysis: Ad hoc interactive queries are a good fit for Spark on Lambda as we can provision a large amount of compute power quickly.
- Stream Processing: Processing a discrete flow of events is also a candidate use case for Spark on Lambda.
Key Challenges
While AWS Lambda comes with the promise of fast burst provisioning of nearly infinite cloud computing resources – it has some limitations that make it a challenge to run Spark. Our implementation had to overcome these key challenges:
- Inability to communicate directly: Spark using the DAG execution framework spawns jobs with multiple stages. For inter-stage communication, Spark requires data transfer across executors. AWS Lambda does not allow communication between two Lambda functions. This poses a challenge for running executors in this environment.
- Extremely limited runtime resources: AWS Lambda invocations are currently limited to a maximum execution duration of 5 minutes, 1536 MB memory, and 512 MB disk space. Spark loves memory, can have a large disk footprint and can spawn long-running tasks. This makes Lambda a difficult environment to run Spark on.
These limitations force non-trivial changes to Spark to make it run successfully on Lambda.
In the following sections, we describe the changes to make Spark work on serverless runtimes like AWS Lambda and the applications that were run using Spark on Lambda.
Implementation
The implementation is based on two key architectural changes to Spark:
- Spark executors are run from within an AWS Lambda invocation.
- Shuffle operations use external storage to avoid limits on the size of local disk and to avoid inter-communication between Lambda invocations.
Setup
Qubole
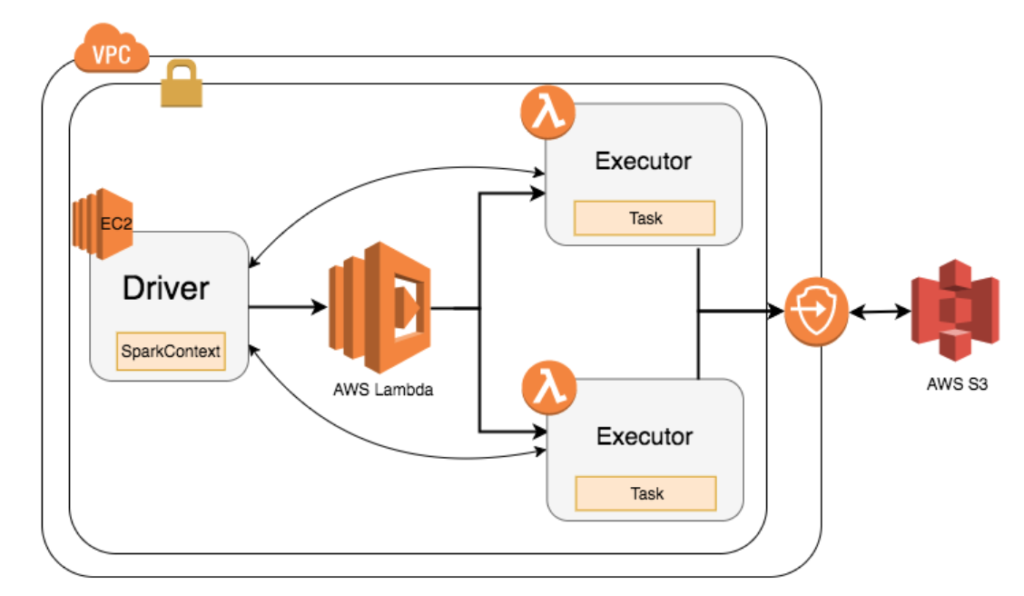
Running Apache Spark on AWS Lambda
The Spark driver JVM runs on an EC2 instance in a VPC. The security group on the EC2 instance running Spark driver allows incoming connections from the executors running on Lambda. The Lambda functions are run as a part of the same VPC.
We have skimmed Spark, Hadoop, and Hive distribution (jars) to create a smaller package that can be deployed within the 512MB disk limit of the Lambda instance.
Spark Executors as Lambda Functions
Generally, Spark Executors are launched on machines with a lot of disk space where Spark libraries are pre-installed. However, AWS Lambda functions can only be launched with a maximum deployment package size of 50 MB (.zip/.jar file). In order to be able to run Spark Executors via Lambda, we:
- Launch AWS Lambda using a barebones Python Lambda function.
- Immediately after launch, the Python code bootstraps Lambda runtime by downloading Spark libraries from a zipped S3 package extracts the archive under /tmp (only writable location in Lambda) and starts the Spark Executor by executing the Java command line passed as part of the Lambda request.
- This Executor then joins the Spark application by sending heartbeats back to the Spark Driver
Starting executors from scratch with the above strategy can be fairly slow. However, AWS Lambda allows subsequent instances of the executor to start up much faster than the first call. In the cold start case, we observed an executor start-up time to be around 2 minutes. Comparatively, in the warm case (where Lambda already has a provisioned container), we noticed a startup time of around 4 seconds. This is in contrast to provisioning EC2 instances required for capacity expansion that takes around one to two minutes to become operational.
New Spark Scheduler
Spark has a pluggable scheduler backend known as CoarseGrainedSchedulerBackend that works with different cluster managers like Apache Hadoop YARN, Mesos, Kubernetes, Standalone, etc for requesting resources. Spark driver internally creates the respective scheduler backend during the launch of the Spark application which deals with the registration of the application, stopping the application, requesting more executors, or killing of existing executors. For example, in the case of YARN as the cluster manager, YarnSchedulerBackend submits the YARN application along with the necessary information to launch an ApplicationMaster to the YARN’s ResourceManager using the YARN client. Once the application is accepted by ResourceManager, it will launch the ApplicationMaster which helps in negotiating resources with YARN throughout the lifecycle of the Spark application.
Similarly, we implemented a new backend for AWS Lambda. Whenever the Spark driver needs more resources, the LambdaSchedulerBackend makes an API call to AWS Lambda to get a Lambda invocation. Once the invocation is available, the Executor is started as described previously. Once the executor’s 5-minute runtime is exhausted, Spark’s auto-scaling component decides to ask for new executors, and new API calls are made to AWS Lambda.
An additional change to the Spark scheduler also stops the scheduling of tasks to an executor once it is close to the expiry of its execution duration time. To reduce the possibility of failures of running tasks, the scheduler stops assigning tasks to such executors after a configurable interval (4 minutes in our case).
During our experiments, we also noticed that AWS Lambda starts throttling the requests after a certain rate is exceeded. To account for these, we modified the Scheduler backend to make requests at a constant linear rate instead of making a large number of requests at once.
State Offload
The changes to Spark shuffle infrastructure are an important change we had to make to run Spark on Lambda. The stateless architecture of Lambda, its run time limits, and the inability to communicate between two Lambda functions meant that we need an external store to manage the state. With Lambda being an AWS service, S3 became an automatic choice to store the shuffle data. The mapper tasks write the data directly to S3 using a directory layout scheme, which allows any executor (tasks in the downstream stage) to read the shuffle data without the need for an external shuffle service. The writes to S3 are performed using a stream mechanism in which large files/streams are uploaded in the form of blocks.
Although, we initially ran all the experiments using S3 as a shuffle store, internally we use the Hadoop file system, which makes the shuffle store pluggable. This makes it possible to replace S3 as a shuffle store with HDFS or Amazon Elastic File System (EFS) easily.
In this architecture, since the shuffle data of tasks persisted to S3, we also made scheduler changes to avoid the need to resubmit a stage for handling executor (Lambda) failures.
Performance Measurements
The big question is how this implementation performs on everyday use cases that we set out to solve. Results on two simple and realistic use cases are reported next.
Scanning 1 TB of Data
A line count operation on a dataset involving a read of 1 TB data using 1000 Lambda executors took only 47 seconds. Given AWS’s cost of $0.000002501 per 100ms compute time – the cost turns out to be $1.18.
The time spent is in sharp contrast to the amount of time required to bring up a cluster and perform the same operation. The average time to bring up a Spark cluster in the cloud requires 2-3 minutes. For an already running cluster with sufficient capacity, the memory requirements and concurrency of this operation would have required at least 50 r3.xlarge instances, an additional overhead to maintain and optimize the lifecycle of these instances.
Sorting 100 GB of data
Using Spark on Lambda we were able to sort 100 GB of data in little less than 10 minutes (exactly 579.7s) with 400 concurrent executors running at any time with a total of 800 Lambda functions.
Technical details:
- We found 128 MB to be the right split size. A split size of 64 MB results in lots of S3 calls that introduce latencies and increase the end-to-end runtime of the application. On the other hand, processing of 256 MB split size hits the memory limit of AWS Lambda execution.
- AWS Lambda can execute thousands of Lambda functions concurrently. For this application, we had to limit it to 400 concurrent Lambda functions as the concurrent write of shuffle data to a bucket led to throttling from the S3 service. Though, this can be overcome by making changes to the shuffle write scheme and partitioning writes based on a prefix generated by an application.
The setup shall also be extendable to sort larger datasets as well.
Cost Estimate
Overall it took 1000 Lambda functions running for 5 minutes with 1.5 GB of memory. Lambda function with this specification costs $0.000002501 per 100ms.
Total cost = $0.000002501 * 5 * 60 * 10 * 1000 = $7.5
This is definitely expensive but this is due to occasional S3 throttling, expiring Lambda execution duration causing the task to fail and to be retried. It both costs as well as adds up to the time. We have listed a few changes in the future work section below that shall help in reducing the runtime of this benchmark and result in lower Lambda costs. This example also reiterates the fact that applications that need large amounts of data to be preserved as a state, can enjoy the benefits of Lambda such as simplicity, elasticity, and transparency but might incur additional cost overhead.
GitHub Repository
The code for Apache Spark (based on version 2.1.0) to work with AWS Lambda is available at https://github.com/qubole/spark-on-lambda.
Future Work
The above work has helped in classifying applications that can be a great fit for Spark on Lambda. We have also identified additional areas where improvements can be made to increase the scale and subset of suitable applications:
- Scheduler: AWS Lambda limits the maximum execution duration to 5 minutes. One can go beyond the scheduling changes suggested above and intelligently schedule tasks by looking at the maximum run time of a task in a stage and not schedule it on an executor on Lambda that doesn’t have sufficient remaining execution duration.
- Shuffle: With AWS S3 occasional eventual consistency issues can arise as a result of rename operation on shuffle data. These renames on S3 can either be eliminated or handled in a manner to avoid eventual consistent operation.
- Shuffle: With more than 400 concurrent Lambda executions and write to an S3 bucket, the application can experience throttling. This can be scaled for better performance by partitioning the shuffle data written to S3 with a unique prefix to perform load balancing of keys.
- Shuffle: The latency while fetching multiple shuffle blocks from S3 can be masked by parallelizing these requests in the new block fetcher added for Spark on Lambda functionality.
- The executor brings up and shuffles data write times can be further optimized if AWS Lambda has support for other scalable file storage solutions such as AWS Elastic File System (EFS)
Come visit us at re:Invent
Qubole will be demonstrating Spark on AWS Lambda at AWS re:Invent 2017 in Las Vegas at Sands Expo booth 834 and Aria booth 201. We look forward to seeing you there!



