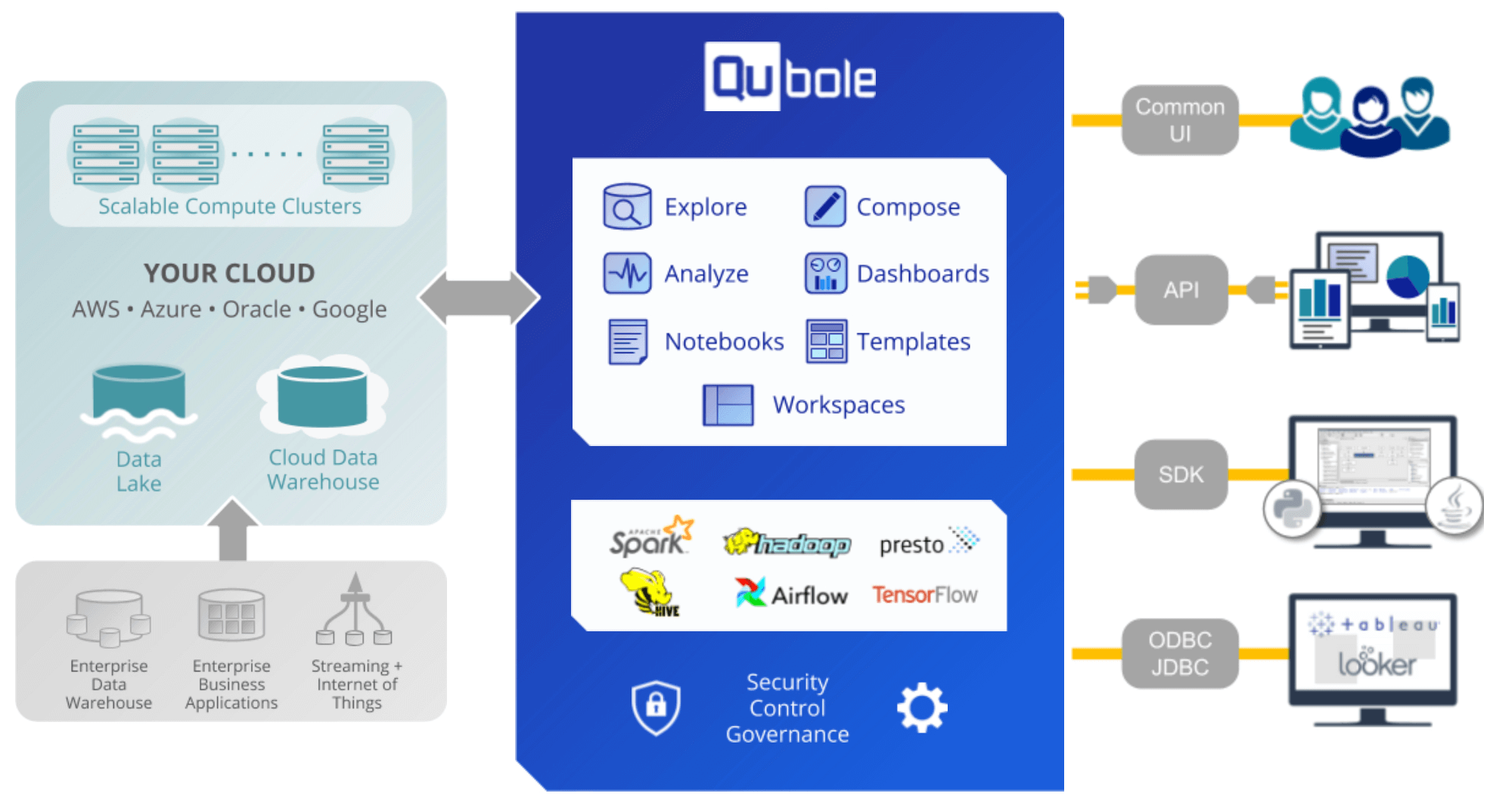
CLOUD-NATIVE ARCHITECTURE
Cloud Infrastructure
Qubole’s cloud-native data platform runs on your choice of cloud infrastructure, by leveraging your own virtual private cloud (AWS or Google).


Users have the same self-service experience on all clouds, regardless of the interface used to access data and processing engines—whether it is Qubole’s native UIs, Qubole Notebooks, REST APIs, SDK, third-party tools like Looker or Tableau, or through generic ODBC/JDBC connections.
Cloud Elasticity
Equally, Qubole’s self-optimizing capabilities for automatically scaling to meet workload requirements with the lowest operational cost possible are the same in all clouds. The platform intelligently optimizes resources to assign more capacity when needed, and releases resources when workloads require less capacity using regular compute nodes or low-cost nodes (AWS’ Spot instances or Google’s Preemptible VMs).
For more details, click on the respective pages for Qubole on Amazon Web Services, and Google Cloud; or sign up for Qubole’s 30-day free trial.