RubiX - A Cache Framework for Cloud Platforms
RubiX is a lightweight data caching framework that can be used by SQL-on-Hadoop engines. RubiX is designed to work with cloud storage systems like AWS S3 and Azure Blob Storage. Rubix can be extended to support any engine that accesses data in cloud stores using the Hadoop FileSystem interface via plugins. Using the same plugins, RubiX can also be extended to support other cloud stores as well.
Benchmarks
This chart plots the time taken without caching vs the time taken with RubiX
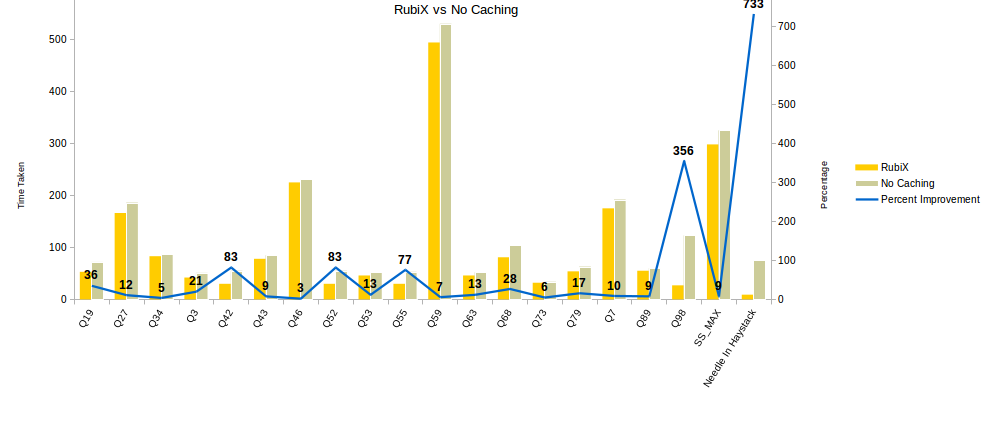
We saw improvements as big as 8x, with the more data being read in a query the higher the improvements. Some queries, as seen in the chart, only saw a slight improvement because they were not computed intensively. In such cases, the cache is not of as much benefit.
Benefits
Columnar Caching for faster warmup times
RubiX is a FileSystem Cache and works with files and byte ranges. The advantage is that only byte ranges that are required are read and cached. Such a system works well with columnar format readers like ORC and Parquet which request only certain columns stored in specific byte ranges.

Engine Independent Scheduling Logic
RubiX decides which node will handle a particular split of the file and always returns the same node for that split to the scheduler, thereby allowing schedulers to use locality-based scheduling. RubiX uses consistent hashing to figure out where the block should reside. Consistent hashing allows us to bring down the cost of rebalancing the cache when nodes join or leave the cluster, e.g. during auto-scaling.

Shared Cache across JVMs
RubiX has a Cache Manager on every node which manages all the blocks that are cached. Every job whether it runs in the same JVM (Presto) or separate JVMs (Spark) refers to the cache manager to read blocks.


