How to Optimize Spark Clusters on Qubole for Cost Reliability and Performance
This second blog from the three-part series explains how a Spark cluster on Qubole can be configured to achieve higher Spot utilization, which optimizes the job for lower costs while ensuring reliability.
The first blog explained how you can leverage heterogeneous configurations in Qubole clusters to maximize your chances of getting spot nodes.
Spark Cluster Configuration to Maximize Spot Utilization:
Spot nodes come at a heavily discounted price compared to On-Demand or Reserved nodes. Higher Spot utilization equates to greater cloud cost savings. Qubole provides features that help maximize the chances of getting Spot nodes and ensure that the cluster always maintains the desired Spot utilization. Additionally, the platform has built-in intelligence to reduce Spot loss risk, and job failure risks associated with Spot loss.
Qubole provides 4 easy steps to configure a cluster, which include features that are tailored to maximize Spot utilization while mitigating Spot loss risk.
Let’s see what the original cluster configurations were, the changes we made, and the impact that the changes had on cluster performance.
- Autoscaling boundaries: Qubole provides this feature to ensure that the cluster has the optimal capacity to meet SLAs of ongoing workloads. The feature avoids job failures due to insufficient capacity in undersized clusters, and resource waste due to excessive capacity in oversized clusters in on-premises setups—thus helping data teams avoid unnecessary cloud costs. For the problem at hand, the cluster was configured to use 3 minimum worker nodes and autoscale up to a maximum of 250 worker nodes.
- Desired Spot utilization: This feature ensures that the cluster maintains a certain percentage of Spot nodes the cluster, which directly equates to the cloud cost savings. The cluster was configured to have the desired Spot utilization of 80%. This meant that Qubole had to maintain 80% of total autoscaling nodes as Spot nodes. In a completely scaled-out scenario for this cluster when the cluster had 250 worker nodes running, this meant Qubole had to maintain about 197 Spot nodes.
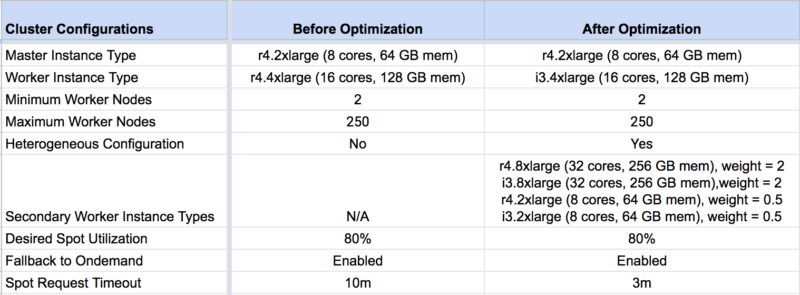
- Heterogeneous configurations: This feature ensures that the cluster has the required spot capacity (cores and memory) even in cases where AWS is not able to fulfill the requested capacity for the configured primary worker instance type. Heterogeneous config was NOT enabled in the cluster.
- Fallback to On-demand: This feature ensures that the cluster has the required capacity (cores and memory) even in cases where AWS is not able to fulfill the requested Spot capacity for the configured worker instance type. If the cluster is configured to use this feature, Qubole will fall back to on-demand nodes in those circumstances. This configuration was enabled in the cluster.
Using Qubole Cost Explorer to optimize Spark Clusters for Spot Utilization
Leveraging Qubole Cost Explorer, I decided to take a holistic view of the problem at hand.
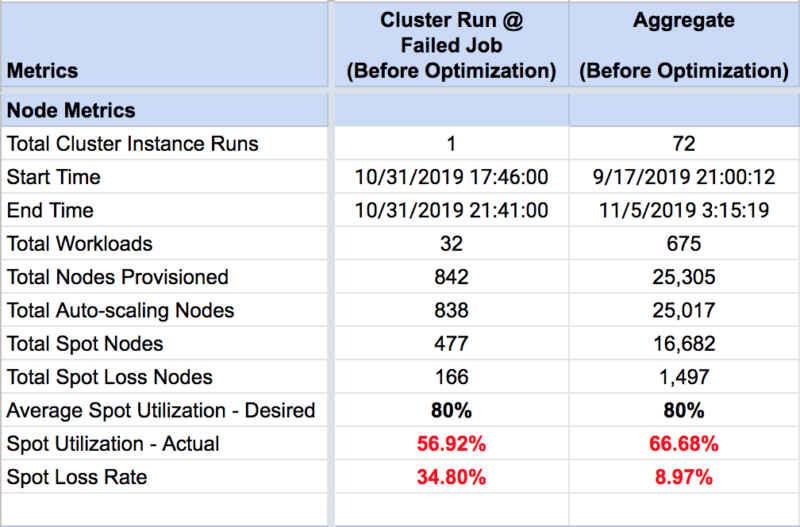
- Total Cluster Instance Runs = 72
Qubole provides an automated Cluster Life Cycle Management capability that:- Automatically starts clusters upon the arrival of a first workload or at a scheduled interval,
- Automatically scales up when the demand for more capacity increases either due to higher concurrency or the bursty nature of workloads
- Automatically scales down when workloads finish and
- Auto-terminates a cluster when it is idle for a pre-configured period specified as “idle cluster timeout.”
This particular cluster was auto-started 72 times.
- Node Metrics:
Observations:
- 33 out of 72 cluster instance runs experienced Spot loss. Spot loss risk is higher with AWS instance types that are high in demand. In this particular case, all Spot nodes that experienced Spot loss were of type r4.4xlarge.
- Desired Spot utilization for the cluster was 80% and the actual (i.e: realized) overall Spot utilization was 66.68%.
- Spot utilization during the specific cluster run when command failure occurred was 56.92%. That gave us a clue that Spot availability for the configured AWS instance type was low.
- The spot loss rate for the cluster across all cluster instance runs was 8.97% and that rate shot up to 34.80% during the specific cluster run when command failure occurred.
From the metrics, it was evident that the cluster was experiencing performance problems due to an unusually high Spot loss rate (34.80%), which was exacerbated by the Spot utilization (56.92%) in the cluster.
The Solution:
The solution implemented to address this problem was two-fold:
- Eliminate spot loss risk while leveraging higher spot utilization in the cluster and
- Engine level enhancements to effectively handle spot loss nodes and ensure reliability.
Spark Cluster Configuration Tips for Spot Utilization Maximization:
The following recommendations were based on the data points captured at the time when the incident occurred. Keep in mind that Spot availability in the AWS Spot market changes frequently.
- Choose instance types with lower service interruption rates in the desired VPC region. A lower service interruption rate means higher reliability for tasks running on that instance and thus provides cost benefits associated with Spot instances (read: greater discount). Follow these guidelines to find lower service interruption instances:
- You can check current service interruption rates here.
- Instances with a service interruption rate of <5% have a lower Spot loss risk.
- For example, r4.4xlarge has a service interruption rate of 5-10%. Whereas i3.4xlarge has a service interruption rate <5%.
- Use heterogeneous configuration for the Spark on Qubole cluster, with at least 5 secondary worker instance types. A heterogeneous configuration with multiple secondary worker instance types maximizes the chances of getting Spot nodes in scenarios where a primary worker instance type is not available in the Spot market at the time of bidding due to high demand. This avoids the unnecessary spike in cloud costs during such periods, resulting in lower cloud costs.
- Ensure that Spot fleet policy is in place for heterogeneous configuration for Spot requests to work – here.
- In our example, for the customer’s region, r4.8xlarge, i3.8xlarge, r4.2xlarge, i3.2xlarge were the better candidates with a lower service interruption rate of < 5% at that time.
- Use secondary worker instance types across different instance families.
- Generally, when an AWS instance type is experiencing Spot loss due to high demand and low availability, the availability of other instance types from the same family is also impacted. In such scenarios, having secondary worker instance types from different families ensures that the desired capacity is still fulfilled using Spot nodes belonging to secondary worker instance types. This avoids unnecessary spikes in cloud costs during such periods.
- Reduce Spot Request Timeout. Link to cost-saving and/or reliability
- Generally, the Spot loss risk for a given Spot node is directly proportional to the amount of time taken to acquire that node. A lower Spot request timeout helps acquire relatively stable Spot nodes in the cluster and ensures reliability in the cluster. Qubole’s intelligent Spot rebalancer, which periodically runs as a background process in the cluster, monitors and corrects the Spot utilization in the cluster to the desired configuration.
- Choose instance types with lower service interruption rates in the desired VPC region. A lower service interruption rate means higher reliability for tasks running on that instance and thus provides cost benefits associated with Spot instances (read: greater discount). Follow these guidelines to find lower service interruption instances:
Qubole Spark Enhanced Handling of Spot Node Loss:
In the meantime, Qubole Spark also enhanced the handling of the Spot Node Loss in the Engine. Enhancement made Qubole Spark more reliable in the event of Spot Node Losses. Following State Machine explains the algorithm used to handle Spot Node Loss effectively:
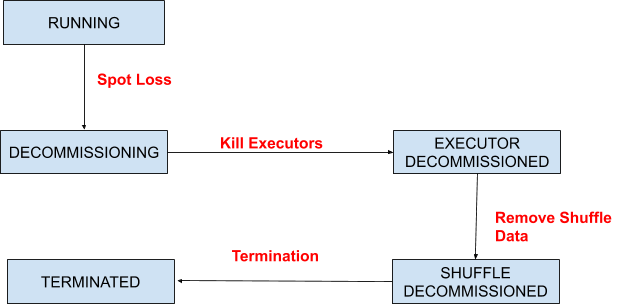
- AWS sends the spot loss notification about two minutes prior to taking away the spot nodes. Upon receiving such Spot Node Loss notification, Qubole puts the impacted nodes into DECOMMISSIONING state. Additionally, Qubole ensures that no new tasks are assigned to nodes in this state.
- Before the Spot node is lost, Qubole Spark kills all the executors running on the node. This is done to ensure the fast failure of tasks so that they can be retried on other surviving nodes. There might be tasks that could have finished within the time boundary AWS takes away the node. To avoid such scenarios, Qubole Spark waits for a configurable period of time before killing the executor. That waiting period can be configured by setting the following property – `spark.qubole.graceful.decommission.executor.leasetimePct`. After killing the executors, Node is put into an EXECUTOR DECOMMISSIONED state.
- After executors are killed, all the map outputs from the host are deleted from MapOutputTracker. This is to avoid other executors from reading the shuffle data from this node and failing due to FetchFailedExceptions. Node is put into SHUFFLE DECOMMISSIONED state.
- After Node is terminated, move it to TERMINATED state.
- Even when Map Outputs are cleared from the node (before moving it to the SHUFFLE DECOMMISSIONED state), there will be stages that would have started reading shuffle data earlier. Those stages will fail due to FetchFailureException after the Spot node is lost. Such FetchFailedException due to Spot Node Loss are ignored and stages are retried. Moreover, such retries are not counted towards failures bounded by the spark.stage.maxConsecutiveAttempts (which is 4 by default). However, there is a threshold on the number of times they can experience failure due to SpotNode loss which can be configured via spark.qubole.graceful.decommission.fetchfailed.ignore.threshold.
Impact Summary:
The table below depicts before and after cluster configurations and numbers of the cluster optimization recommendations that were implemented in the customer’s cluster.
Before and After Configurations:
Before and After Metrics:
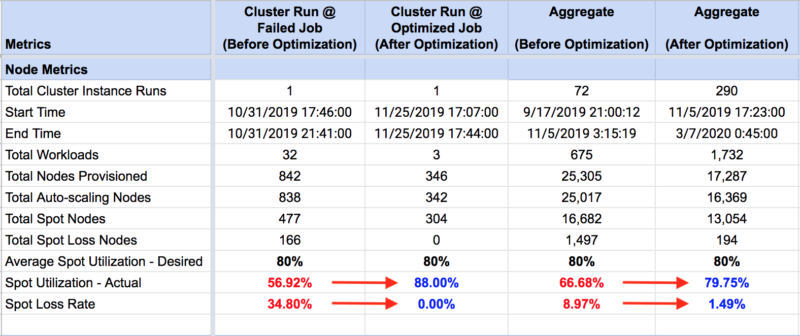
- 15.63% increase in Average Spot Utilization (from 66.68% to 79.75%) leading to greater cloud cost savings.
- 83.39% drop in Average Spot Loss Rate (from 8.97% to 1.49%) leading to greater cloud cost savings and greater performance.
- Additionally, we did not observe spot loss-related failures after the engine optimizations were rolled out.
Thus, with improved spot utilization and reduced spot loss rate customer’s spark cluster was optimized for cost while ensuring that the reliability was not impacted.
In the next blog, I will cover how we fine-tuned customers’ spark jobs for better performance using Qubole Sparklens, a tool we open-sourced for visualizing and optimizing jobs in Spark.
Meanwhile, sign up for a free 14-day trial to experience the power of Spark on Qubole.



